tags:
- OS
- File Systems
第一课 Peek into File System
我们使用计算机,对文件并不陌生。文件有许多不同的格式。在完成程序设计实验中,我们就接触了 .c/.cpp 源代码文件,编译生成 exe 或 elf 格式的可执行文件格式,还有一般实验报告递交的 doc 文件格式。我们的生活离不开这些由文件系统管理的不同类别的文件。此外,文件系统还涉及文件的检索和保护,影响系统的性能和可靠性。对于操作系统,文件系统至关重要。
1.1 Persistent Storage
内存是计算机的核心部件之一,然而内存并不能提供持久性的存储,内存中的数据信息会由于系统的关闭或掉电而丢失掉。为了避免这种情况,我们需要一种能够在掉电后保证数据的完整性的存储介质。实际上,不易失的存储介质有很多,HDD、SSD、CD等。在文件系统的应用上,现多采用HDD和SSD作为文件系统的存储介质。
1.1.1 HDD

1.1.2 SSD

1.2 File Concept
既然我们说到了文件系统,那我们的话题必然离不开文件。我们时时刻刻在使用着各种各样的文件,那文件是什么?文件是存储在永久性存储介质上相关数据的集合。文件可以是常见的文本、照片、视频,还可以是系统配置、代码等信息。文件的功能有:数据存储、数据交换和数据保护等。

1.2.1 File Metadata
文件元数据(File Metadata),也被称为文件属性(File Attributes),包含对文件特征的描述信息,文件元数据并不作为文件数据,而是存储在文件系统的目录结构中。常见的文件属性有:
- 文件名:人类可读文件的标识符,区别于其他文件。
- 文件标识符:唯一的文件id,与其他文件进行区分。
- 文件类型:操作系统需要文件类型信息才能提供相应的支持。
- 文件路径:文件在文件系统中的位置。
- 文件大小:文件占用存储空间的大小。
- 时间戳:记录创建、修改的时间等。
- 链接计数
- 文件权限
- 文件所有者和用户组
- 访问次数等。
1.2.2 File Types
通过对文件的类型进行分类,文件可以被分为普通文件、目录文件、符号链接文件、特殊文件、套接字文件和管道文件。
文件类型是无穷多的,而操作系统并不能直接识别和解析所有类型的文件。虽然操作系统可以识别文件的基本类型(例如,通过文件扩展名或文件头信息),但要打开和正确显示特定类型的文件就需要安装相应的软件。典型的有Java的可执行字节流,这是一种二进制程序文件,但要是系统上没有安装 JVM,操作系统就无法直接运行这些Java字节码文件。
1.2.2.1 Regular Files
常规文件是文件系统中标准的文件类型,也是最常见到的文件类型。常规文件类型包括文本文件、二进制文件、图像文件、音频文件、视频文件等。为了操作系统能够加载并执行程序,所以操作系统必须至少完全支持一种可执行文件类型。
1.2.2.2 Directories
目录文件(directory files) 是一类特殊的文件,它记录着文件目录(file directories) 的信息。文件目录不仅仅包含数据,也包括对其他文件和子目录的引用。在 Linux 中,目录文件会被标注d属性,说明这个文件的内容实则是一个目录项清单,可用ls "directory file name"命令查看这个清单。
一般而言,目录文件中的内容我们一般是无法查看的,但我们可用通过ls命令来列出目录文件中引用的文件,也可用cd命令来进入目录文件记录的文件目录中。
du@du-virtual-machine:~/Desktop/OS$ ls -alh
total 136K
drwxrwxr-x 3 du du 4.0K 8月 23 00:50 .
drwxr-xr-x 7 du du 4.0K 8月 8 05:09 ..
drwxrwxr-x 2 du du 4.0K 7月 1 00:51 a_file_dir
d属性就表示这是一个目录文件。文件目录以目录文件的显示存储在磁盘上。我们可以通过tree命令以树状结构显示目标目录及其子目录中的所有文件和目录。
1.2.2.3 Symbolic Links
符号链接实际上就是软连接(soft link),之后再介绍文件目录的时候会提到。
1.2.2.4 Special Files
1.2.2.5 Sockets
套接字和FIFO文件在IPC的阶段6.5 Inter-Process Communications里我们已经了解过了。虽然它们的地位较为显赫,但此处不做赘述。
1.2.2.6 FIFO(Named Pipes)
1.3 File System Structure Design
在用户眼中,文件系统为我们提供了许多的便利,通过系统为我们提供的窗口(如:open()等的系统调用),用户并不需要了解这一切是怎么实现的。然而,负责文件系统结构设计的系统设计人员要做的可就多了。接下来,让我们从宏观的角度一层一层地了解下文件系统结构的设计。

1.3.1 I/O Control
文件都是存放在磁盘上的,文件系统的职责是把各种各样的信息数据存放到非易失的存储介质上面。作为I/O设备,我们知道用户任何的请求都会转换成控制磁盘I/O的低级硬件指令交给I/O控制器处理。I/O控制层会收到basic file system layer的高级指令(如:read disk block 1),然后将其转换成磁盘能够理解的指令。又由于外设的低速性,我们对磁盘的操作一般是DMA的I/O控制方式。
具体来说,应用程序先是发出读文件的请求,这些请求经过层次转换到磁盘驱动程序将转换后的磁盘控制器命令交给CPU,然后CPU下达DMA控制操作,DMA控制器直接在内存和磁盘之间传输数据,而不需要CPU的持续干预。这种方式大大提高了数据传输效率,减少了CPU的负担。
1.3.2 Basic File System Layer
基本文件系统负责与硬件交互,是文件系统中开始与硬盘硬件对接的层次。它会向磁盘驱动程序发布指定扇区的读写命令,之后由磁盘控制器驱动程序将命令传给磁盘控制器,控制器执行并返回结果,最终将结果交给操作系统。在这一层次中,对文件的操作是在物理磁盘上的,类似于磁盘1、12号柱面、7号磁道、1号扇区这样精确的磁盘访问请求就发生在这个层次。
由于磁盘访问的低速,在系统中实际上存在了许多buffers和caches来应对访问磁盘带来的开销。所以在这一层次,我们还需要考虑这些系统中存在的buffers和caches。只有当前要访问的数据不在这些buffers/caches中时,我们才需要考虑访问磁盘。也因此,我们需要承担突然断电时带来的数据丢失问题。
1.3.3 File Organization Module
用户总希望自己的文件在系统中是连续存放的,正如我们之前学习虚拟存储技术时了解过的一样,即便我们看到的文件是连续的,但文件在磁盘上的存储块不一定是连续的。因此我们需要一个模块将逻辑块转换成底层硬件能够识别的物理块。
这种逻辑到物理上的转换就是由文件组织模块(File organization module),也叫块管理器提供的。它是一个映射器(mapper),将逻辑块地址映射成物理块地址。文件组织模块维护一个映射表,将文件的逻辑块转换为磁盘上的物理块地址,同时它也管理空闲空间列表,用于跟踪为分配的物理块。
除此,这一模块还负责空闲空间的管理,我们之后介绍。
1.3.4 Logical File System Layer
对于用户而言,一个屏蔽底层硬件、简单、易操作的交互接口和能够对文件的属性进行方便管理的接口是ta们最想要的。而这个为用户提供方便接口的文件系统层次就由逻辑文件系统(Logical file system) 所提供。
逻辑文件系统负责管理文件的元数据。管理文件路径解析、文件描述符、权限检查等,并提供文件的操作接口(打开、创建、读和写)为用户使用,用户可以用系统调用(open/read/write等)与该层次交互。该层次也支持对文件的逻辑访问(逻辑上的文件)。
文件的元数据存放在一个叫文件控制块的东西里面,即FCB,在Unix中,文件控制块也叫inode。
1.4 Disk Organization
文件系统非常多,我们有UFS、AFS、ZFS、NTFS、ext2/3/4、FAT32/64等等。这些文件系统各有不同,但是总有一些共同点,比如跟踪磁盘块的个数,多少个空闲块,多少个已被占用的块;还要管理文件目录的结构和各种文件。
1.4.1 Space Layout
在4. System Boots Up阶段中,我们谈到了计算机上电启动的一些内容。要使计算机正常启动,我们至少需要一块磁盘分区(volume)来存放操作系统的相关数据。我们谈到了磁盘分区上的第一个扇区,也叫启动扇区(boot sector)。当我们将视线放宽到整个volume,我们会看到:
- 引导区(Boot block):包含启动代码和磁盘信息,有MBR和GPT的实现方式。
- 目录区(Directory area, FCB):一级、二级、树形等目录实现方式。
- 空闲空间表(Free space table):管理数据区,有位图、空闲链表、成组链接等实现方式。
- 数据区(Data area):连续、链接、索引等实现方式。
在FAT的课程中,我们会结合FAT文件系统来进行介绍。
1.4.2 Disk Partitioning
除了将一块磁盘一整块地使用,我们还可以逻辑上将磁盘分成若干个不同的区块来使用,这种方法也被称为磁盘分区。我们学习过 MBR 和 GPT 两种磁盘分区的方式。简单来说,磁盘分区就是在存储设备上创建一个或多个独立区域的过程,每个区域都可以作为独立的逻辑磁盘被管理使用。
为了管理这些不同的分区,我们需要一个分区表(partition table),有时也被称为超级块(super block) 或 master file table。分区的相关信息就记录在分区表中,这些信息有开始和结束位置、分区类型和大小等。
在Windows中,磁盘分区常常与盘符相关联,每一个分区对应一个盘符(如 C: 、D:、E:等)。虽然一个物理磁盘可以分出多个盘符,但通常而言,一个物理磁盘我们当成一个分区使用。而在Linux系统中,磁盘通常会被分成多个分区,每个分区有不同的用途。例如,根分区(/)、引导分区(/boot)、交换分区(swap)等。
1.4.3 Review: MBR & GPT
磁盘分区表的位置和大小会随着分区方式的不同而不同。我们学习过 MBR 和 GPT 两种分区模式。我们下面介绍这两种方式分区表存放位置。
主引导记录存放在磁盘的第一号扇区中,它包含了引导代码和分区表。MBR的大小通常为512字节,其中的bootloader占据446字节,分区表占据64字节。但如果系统采用 GPT 的分区方式,第一号扇区的大小就可能是 4KB 大小。
GPT(GUID Partition Table):
- LBA0:为了保证向下兼容,第一个扇区 LBA0 存放保护性 MBR。
- LBA1:存放 GPT header。
- LBA2-LBA34:存放GPT分区条目数组(即GPT分区表)。
- 磁盘末尾:分区表的备份。
1.5 Virtual File System
和我们在一台电脑上可以安装多个操作系统一样,我们同样可以在操作系统上安装多个文件系统。但是每个分区只能有一个文件系统。多个分区我们可以有很多文件系统的话,问题就来了。在用户程序中我们使用的是统一的系统调用。当我们用统一接口的系统调用接口访问不同分区(文件系统)中的文件时,如何保证文件的正确访问?
我们的解决方案是:增加一层抽象:虚拟文件系统。我们将不同的文件系统统一交给VFS进行管理。VFS是文件系统之上的一层内核软件层,用于处理 POSIX 文件系统相关的系统调用,给各种不同的文件系统提供统一的操作接口,使得应用程序可以不必关心底层使用哪个文件系统。用户程序可以通过统一的接口来访问不同分区(文件系统)中的文件,而不会遇到兼容性问题。

VFS的作用有两个。一个是上面我们所提到的,无所谓下面文件系统是怎么实现的,我们都可以通过VFS提供的统一接口来对文件进行操作。另一个是将系统中全部的文件进行唯一化标识。VFS通过使用 vnode 数据结构来唯一标识系统中的所有文件。
在传统文件系统中,FCB用于在分区内唯一标识文件,但在不同的分区中,FCB的唯一性无法得到保证。VFS通过 vnode 数据结构解决了这个问题,每个文件对应一个唯一的 vnode,使得即使在不同文件系统甚至在remote file system中,文件也能够被唯一标识。
第二课 File System Operations
2.1 Basic File Operations
对于文件,我们有很多操作,如创建文件、读文件、写文件、移动文件指针的位置(repositioning)、删除文件和文件的截断(truncation)。文件系统为我们提供了这些基本的文件操作的系统调用,下面我们来一起看一看。
2.1.1 Opening and Closing Files
当你对文件进行操作,你需要使用文件描述符(file descriptor)来对文件进行操作。在POSIX系统调用open()中,open()会返回给我们一个fd。而在C标准库中,我们会使用fopen(),其会返回一个指向FILE结构的指针。你可以用int fd = fileno(f);将FILE转换成fd。
#include <stdio.h>
// Use C standard library opening a file.
FILE* f = fopen(argv[1], "r");
if(f == NULL) {
printf("Unable to open the file %s.\n", argv[1]);
return -1;
}
/* Read the file.*/
fclose(f)
/*
Mode options in fopen() function:
r : Open the file for reading only.(File must exist, or return NULL.)
w : Create the file for writing. If file exist, it's overwritten.
a : Open the file, writing data at the end of the file.(a for append)
r+ : Open for read and update.(File must exist, or return NULL.)
w+ : Create the file for reading/writing. If file exist, it's overwritten.
a+ : Same as above, but in rw mode.
*/
#include <stdio.h>
#include <fcntl.h> // For open(), O_RDONLY, O_WRONLY, O_RDWR, and file access modes
#include <unistd.h>// For close(), read(), write(), fsync(), lseek(), and others.
// Use POSIX system call opening a file.
int fd = open(argv[1], O_RDONLY);
if (fd == -1) {
perror("Unable to open the file");
return -1;
}
/* Read the file.*/
close(fd);
以上是两种打开文件的形式,第一种使用C标准库,提供了一种更高级易用的接口,而底下我们使用POSIX系统调用,相比之下更为直接,但是不够user friendly。因为,用户并不知情FILE实际上是一个整数。我们之后会了解到,文件描述符是一个表示打开文件的整数。
以下是打开和关闭文件的POSIX系统调用原型函数:
#include <fcntl.h> // For open(), O_RDONLY, O_WRONLY, O_RDWR, and file access modes
#include <unistd.h>// For close(), read(), write(), fsync(), lseek(), and others.
#include <sys/types.h> // For data types used in some system calls
#include <sys/stat.h> // For file status and mode information
int open(const char *pathname, int flags, ...);
/* Parameters:
1. pathname: Pointer to the name of the file to be opened.
2. flags: File access modes and other flags.
Common flags:
- O_RDONLY: Open for reading only.
- O_WRONLY: Open for writing only.
- O_RDWR: Open for reading and writing.
- O_CREAT: Create the file if it does not exist.
- O_EXCL: Ensure that this call creates the file (fails if the file exists).
- O_NOCTTY: If the pathname refers to a terminal, do not make it the controlling terminal.
- O_TRUNC: Truncate the file to zero length if it already exists and is opened for writing.
- O_APPEND: Open the file in append mode.
- O_NONBLOCK: Open the file in non-blocking mode.
- O_DSYNC: Write operations will complete according to the requirements of synchronized I/O data integrity completion.
- O_SYNC: Write operations will complete according to the requirements of synchronized I/O file integrity completion.
- O_RSYNC: Synchronize read operations.
- O_DIRECT: Minimize or eliminate cache effects of the I/O to and from this file.
Return value: Returns a file descriptor on success, otherwise -1.
*/
int close(int fd);
/* Parameters:
1. fd: File descriptor of the file to be closed.
Return value: Returns 0 on success, otherwise -1.
*/
2.1.2 Seek the Route
以下是读写文件和移动文件指针的 POSIX 系统调用。
off_t lseek(int fd, off_t offset, int whence);
/* Parameters:
1. fd: File descriptor of the file.
2. offset: Offset to set the file position to.
3. whence: Starting point for the offset (SEEK_SET, SEEK_CUR, SEEK_END).
Return value: Returns the resulting offset location on success, otherwise -1.
*/
ssize_t read(int fd, void *buf, size_t count);
/* Parameters:
1. fd: File descriptor of the file to read from.
2. buf: Buffer where the read data will be stored.
3. count: Number of bytes to read.
Return value: Returns the number of bytes read on success, otherwise -1.
*/
ssize_t write(int fd, const void *buf, size_t count);
/* Parameters:
1. fd: File descriptor of the file to write to.
2. buf: Buffer containing the data to be written.
3. count: Number of bytes to write.
Return value: Returns the number of bytes written on success, otherwise -1.
*/
int fsync(int fd);
/* Parameters:
1. fd: File descriptor of the file to be synchronized.
Return value: Returns 0 on success, otherwise -1.
*/
2.1.3 Delete
remove 函数和 unlink 函数在删除文件时的行为是相同的。当我们使用 remove 或 unlink 删除文件时,实际上是删除了文件系统中的一个硬链接。如果文件有多个硬链接,只有指定的那个链接会被删除,文件的内容仍然存在,直到所有的硬链接都被删除为止。
#include <stdio.h>
int remove(const char *filename);
/* Parameters:
1. filename: Pointer to a null-terminated string that specifies the name of the file to be deleted.
Return value: Returns 0 on success, otherwise -1.
*/
#include <unistd.h>
int unlink(const char *pathname);
/* Parameters:
1. pathname: Pointer to a null-terminated string that specifies the name of the file to be deleted.
Return value: Returns 0 on success, otherwise -1.
*/
2.2 File Control Block
我们用文件描述符来对文件进行操作。而fd只是一个整型数,实际上并不能唯一的标识一个文件。就相当于厕所隔间里面的人,在某一刻,你能够确定厕所里就是这个人,你用xx号厕所来标识这个人,但是当这个人离开厕所,这个文件描述符将会失效。即在不同时刻,不同的文件可能使用相同的fd。
2.2.1 FCB
在第一节课,我们提到了文件的元数据,相当于文件的各种信息,这些信息被存储在文件控制块中。操作这些文件的创建修改删除是logical file system layer的工作。当我们要创建一个新的文件,对应着的,一个文件控制块也会随之被创建。系统内,每个文件的文件控制块都是唯一的。

当用户想要读取系统中的某个文件时,操作系统就会把文件的文件控制块加载进内存。由于文件控制块中有文件的元数据,所以系统可以根据文件控制块中文件在磁盘上的位置来加载文件信息。
2.2.2 Inode
Inode实际上就是类Unix系统中的文件控制块。我们将在后续ext文件系统的学习中进行介绍。
2.3 Caching in File System
由于文件系统要频繁地与磁盘进行交互,为了提升存储的性能,我们当然的会想到局部性原理,即caching来提升性能。实际上,文件系统的确有很多caching策略指导的结构。我们有:
- Mount Table
- Cache
- Global Open File Table
- Process Open File Table
- Buffers
为了避免频繁的访问I/O,这些文件系统的结构会被加载进内存中。我们将用演示文件的操作过程演示打开文件表是如何提高系统的效率的。
2.3.1 Open-File Table
我们之前说,进程想要操作文件,就需要FCB中的信息。FCB载入内存需要我们使用open()系统调用,但之前,我们看到open系统调用返回的是fd,和FCB有什么关系?我们接着看。当进程打开文件时,OS就会在进程打开文件表里添加一个新表项。之后,操作系统会检查系统级打开文件表,如果没有找到关于该文件的表项,OS就会创建新的系统打开文件表项来跟踪文件的FCB。
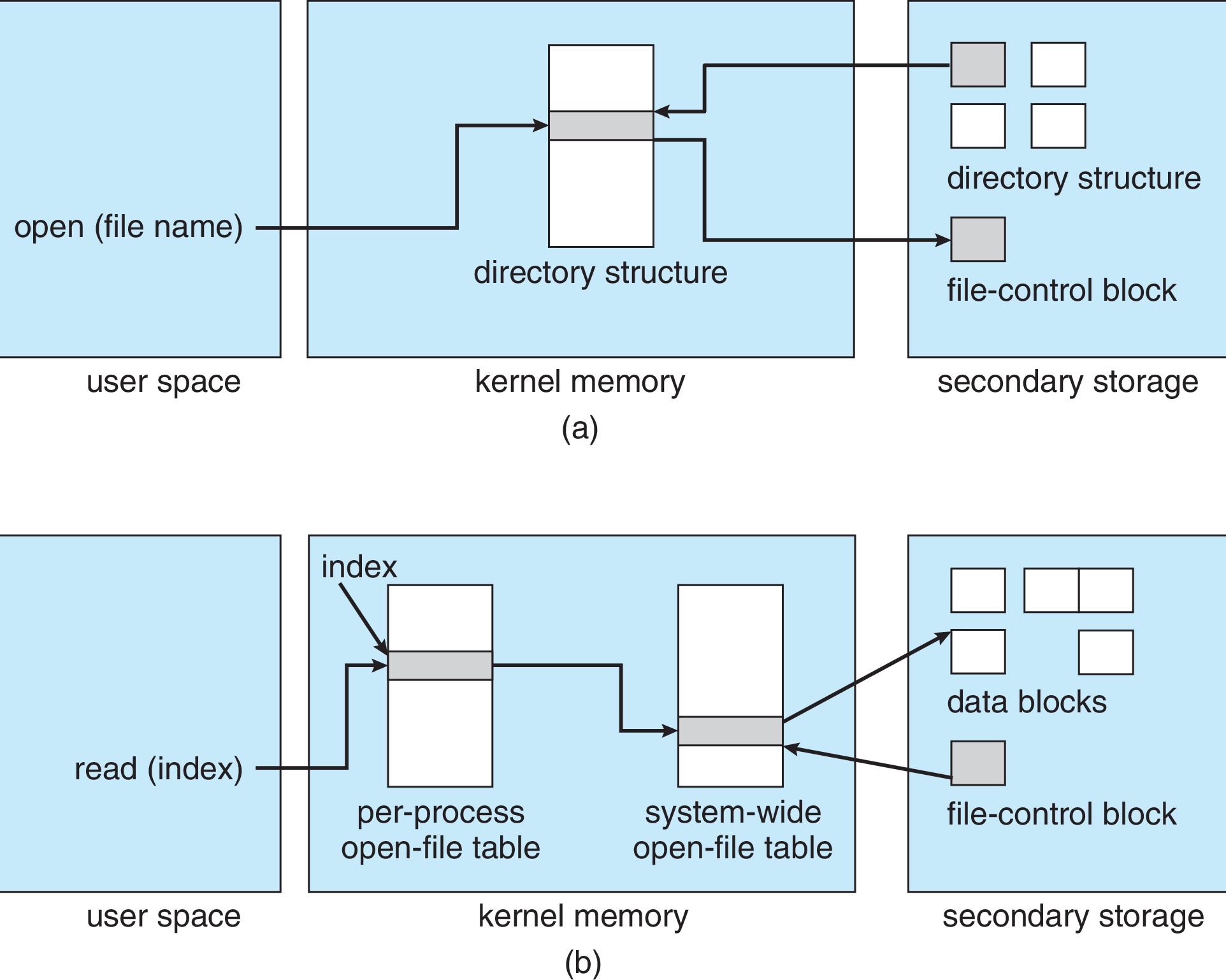
进程打开文件表中存放着系统打开文件表表项的一个索引(fd),便于进程可以通过这个索引找到全局的系统打开文件表里面的表项,进一步对文件进行操作。进程打开文件表每个进程都有一张,每一个条目都对应着进程打开的文件和指向系统级打开文件表的指针,一般而言,进程打开文件表项数为1024,当然你可以将其设置的更高。include/linux/fdtable.h
当FCB加载到内存中后,系统用系统打开文件表对FCBs进行管理,系统打开文件表整个系统只有一张。系统打开文件表项的数据有文件名、文件打开方式、文件偏移量、文件的引用计数和FCB指针等信息。include/linux/fs.h
open文件调用会返回一个指向进程打开文件表中一个特定表项的索引,我们称其为文件描述符/文件句柄(unix中叫做file descriptor,而在windows中叫file handle)。
2.3.2 Where FCBs Went?
当进程要访问文件时,系统会根据文件的目录在磁盘上找到该文件的文件控制块。之后,将所需要的FCB都缓存在内核内存的FCB表/Inode表。然后系统在系统打开文件表中由相关的系统调用信息和FCB信息创建新的表项,其中有文件的一些元数据和一些其他信息。
2.3.3 Open a File
当我们使用open("example.txt", O_RDONLY);时会发生以下情况:
- 进程调用
open("example.txt", O_RDONLY)。
2. 操作系统检查系统级打开文件表,发现 "example.txt" 已经被打开。
3. 在进程级打开文件表中增加一个条目,指向系统级打开文件表中的 "example.txt" 条目,然后在全局的系统打开文件表中对文件的引用计数加一。
4. 返回文件描述符 fd,指向进程级打开文件表中新增加的条目。 - 操作系统检查系统级打开文件表,发现没有打开 "example.txt" 条目
- 在磁盘目录中搜索 "example.txt",如果找到了,那就在系统级打开文件表增加一个条目,将FCB加载到FCB表中,初始打开文件表项。最后将系统的打开文件表中对文件的引用计数设置为1。
- 增加该进程级代开文件表的条目,用指针指向系统级打开文件表的对应条目。
- 返回文件描述符 fd,指向进程级打开文件表中新增加的条目。
在打开文件表中,除了文件的一些元数据外,还要存储文件引用计数信息,即这个文件被系统内的进程打开了多少次。每当使用open()或close()系统调用时,这个数值就会发生改变。只要不为0,该文件的元数据就会一直保留在内存的内核区中。
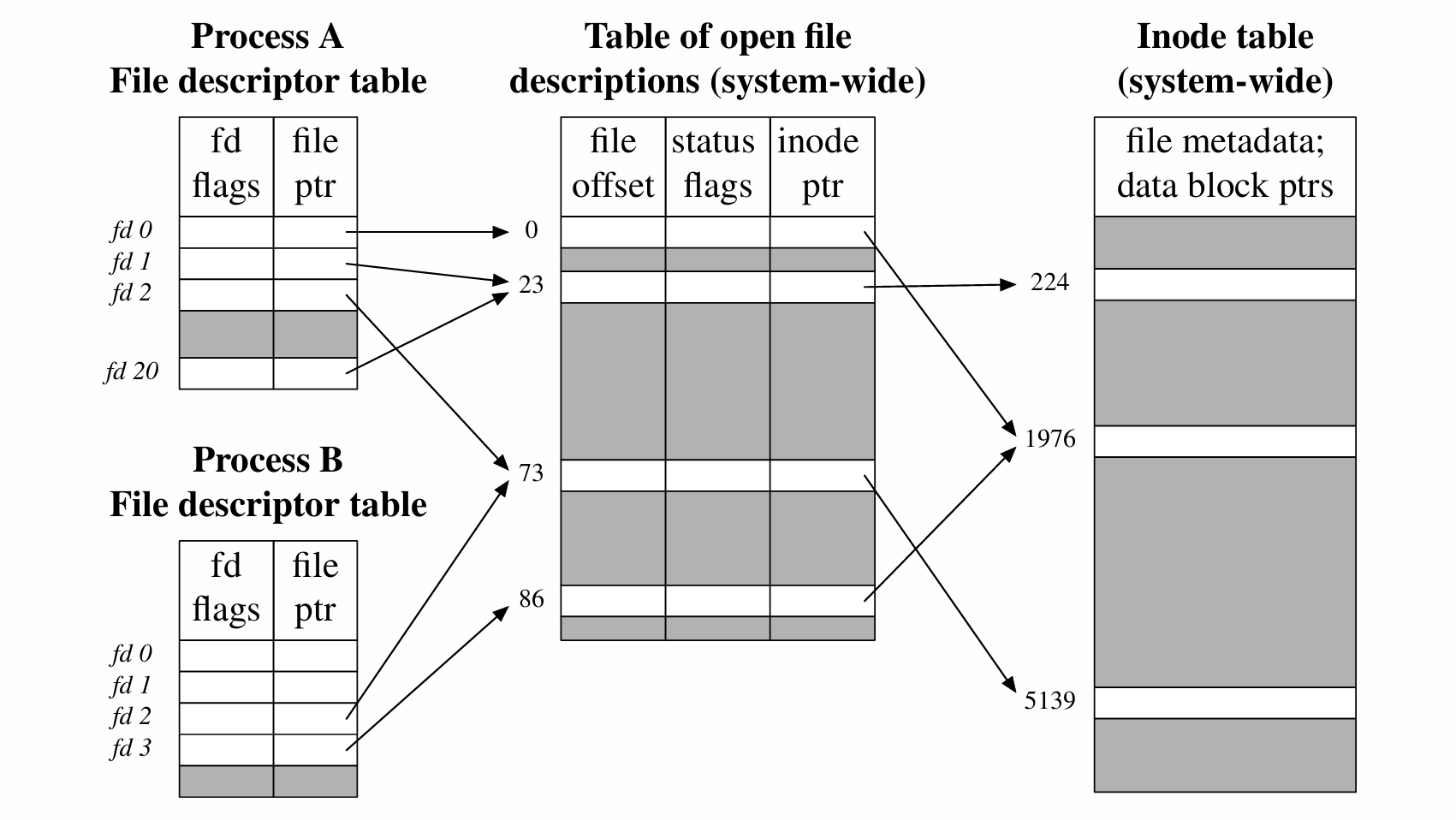
2.3.4 Relationship Between FDs and OFDs
实际上,多个FD(file descriptor) 是可用指向相同的OFD(open file table descriptor)。像如下fd1和fd20都指向偏移为23的OFD(用dup2()复制文件描述符),还有两个进程的fd2都指向偏移为73的OFD(用fork()创建新的子进程)。
2.3.4.1 Different Behaviors of Different FDs
偏移为0的OFD和偏移为86的OFD指向的却是同一个Inode。为什么?这可能是因为两个进程都独立的打开同一个文件。当不同文件描述符的行为不同时,即使多个文件描述符指向同一个文件,每个文件描述符的行为可能因为其具体的使用方式和上下文而有所不同。
比如两个文件描述符维护不同的文件偏移量或是不同的文件状态标志,就会出现多个OFD却指向同一个inode的情况。(说的简单一点就是数据结构不再相同了)
2.3.4.2 Duplicating FDs (dup(fd) and dup2(origfd, newfd))
2.3.4.3 Retrieving and Modifing FDs using fcntl()
第三课 Directory
提到目录,大家都不会陌生。在小学一年级,老师就教过我们用字典目录去查汉字,拿到新的语文课本,我们可能会翻阅目录寻找自己感兴趣的文章去阅读。和”目录“这么久的交情,我们不难给目录下一个定义:目录是一张对内容编排和组织的表,便于我们更好的找到特定的内容。
3.1 File Directory
文件目录就是一张编排组织文件的表(数据结构),便于用户查找相关的文件信息。文件目录容纳其他文件和目录(文件夹),将这些文件和文件夹用某种结构组织起来。有了这种组织,文件和目录管理起来就更加便捷。
3.1.1 Directory Operations
对于文件目录,文件系统需要支持关于目录的很多操作。最基础的就是用文件名来遍历查找文件,这是目录最基本的作用。此外,我们还想知道目录下有哪些文件,所以我们需要支持列出目录文件的功能。要查找文件,我们就得先创建文件,所以还需要支持文件的创建、删除和文件名的修改。
在命令行下,我们能见到很多目录相关的命令,例如:
- 查找文件
find、locate - 创建文件
touch - 删除文件
rm - 显示当前目录
pwd - 列出目录文件
ls - 文件重命名
mv、rename - 创建目录
mkdir - 删除目录
rmdir、rm -r - 切换目录
cd
3.1.2 Directory and FCB
文件的元数据存放在FCB中,文件系统通过FCB来实际控制管理一个文件;而目录是编排组织文件的表,通过目录中对相关文件的指针索引,实际上让我们得以访问对应文件的FCB,从而获取文件的详细信息并进行操作。文件目录以目录文件的形式存储在磁盘上,目录文件存储着系统目录的数据结构信息。
3.2 Directory Structure
为了更好的组织、管理和访问文件,我们选用很多数据结构对文件目录进行记录。以下我们介绍几种构建文件目录时常见的目录形式。
3.2.1 Single-Level Directories
单级目录是最简单的目录结构,所有的文件都放在同一个根目录下。由于这种结构将所有文件放在一起,所以单级目录要求所有文件名必须是唯一的。这种结构是实现起来最简单的,但是文件的命名唯一而且对文件缺少归纳。导致这种目录管理文件就是一摊鸡毛。

在单级目录结构下,没有文件路径的概念。
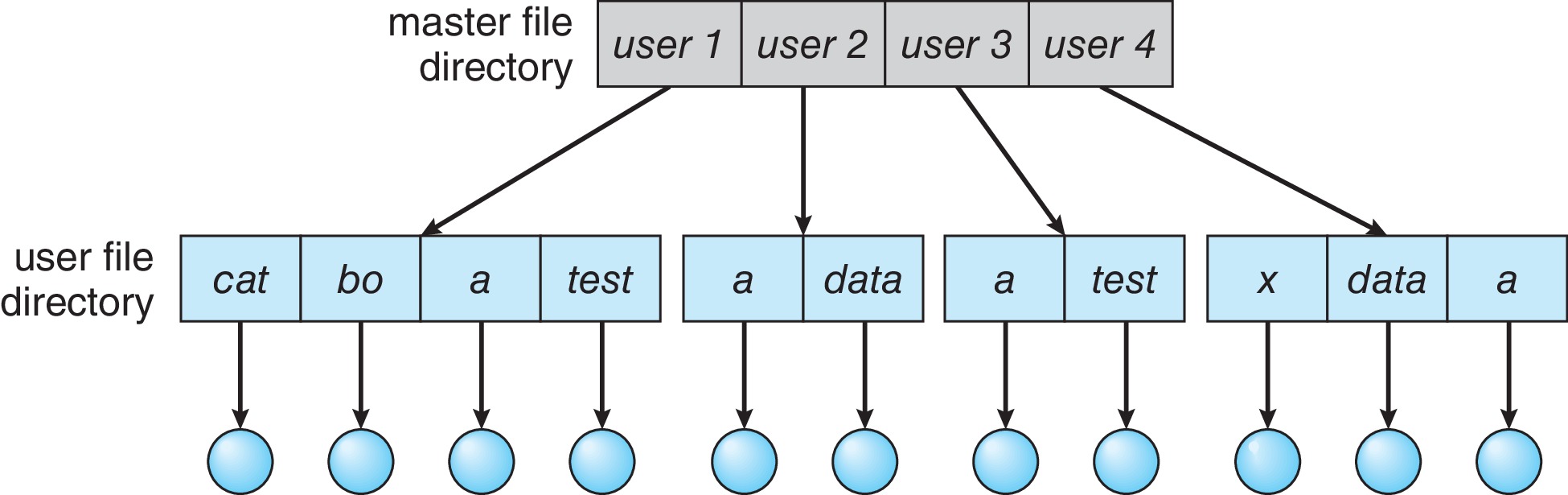
3.2.2 Two-Level Directories
在二级目录结构中,我们有一个主文件目录和子文件目录(sub-directories)。主文件目录可以向下级的用户文件目录提供索引。从而,每个用户可以拥有自己独立的目录来存储和管理文件。解决了一些单级目录中命名冲突问题,并为不同用户提供了文件隔离性。
从二级目录结构开始,文件路径有了意义,每个文件的文件路径(file pathname)在系统中都是唯一的。在引用文件时,如果确定当前的工作目录(用户目录),我们检索不包括用户名的文件时,操作系统会假设文件位于当前的工作目录下。这种不包含文件路径的路径名就是文件相对路径。
而绝对路径是指从根目录开始的完整路径,它包含了从根目录到目标文件或目录的所有目录名。例如,/user1/cat 就是一个绝对路径。无论当前工作目录是什么,通过绝对路径都可以唯一地定位到目标文件或目录。
在用户的目录下,用户无法创建新的目录来对文件进行进一步的归类。
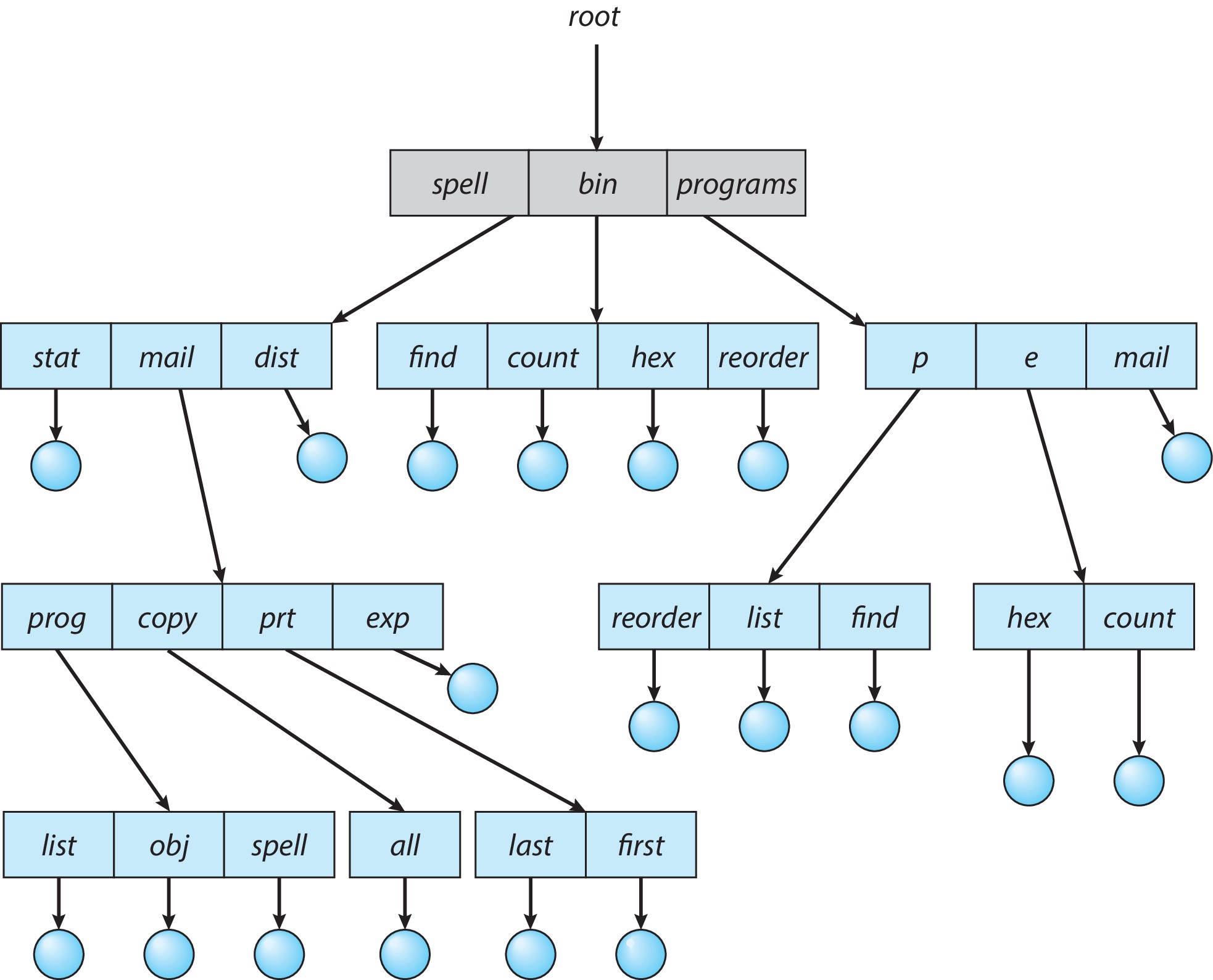
3.2.3 Tree-Structured Directories
树形目录是二级目录结构的升级版,树形结构目录允许子目录创建条目的子目录树,从而消除了文件不能归类的问题。整个目录树有一个根目录,所有的文件或目录都会有包含root的唯一路径名。树形结构为系统带来了更好的灵活性和可变性,在树型结构中,进程可以从一个目录下“跳跃”到另一个目录,也因而,相对目录通常上性能更好(减少了“跳跃”的动作)。在Linux下,我们用"."来指代当前目录(如./hello)。
3.2.4 Acyclic-Graph Directories
上述的三种目录都不能够使得同一个文件/子目录在多个不同的目录下共享,用户访问其他用户的某些文件的愿望将无法得到满足。无环图目录允许一个文件/子目录同时存在于多个目录下,允许文件/子目录在用户多个间共享(不同目录访问同一个文件得到了实现)。
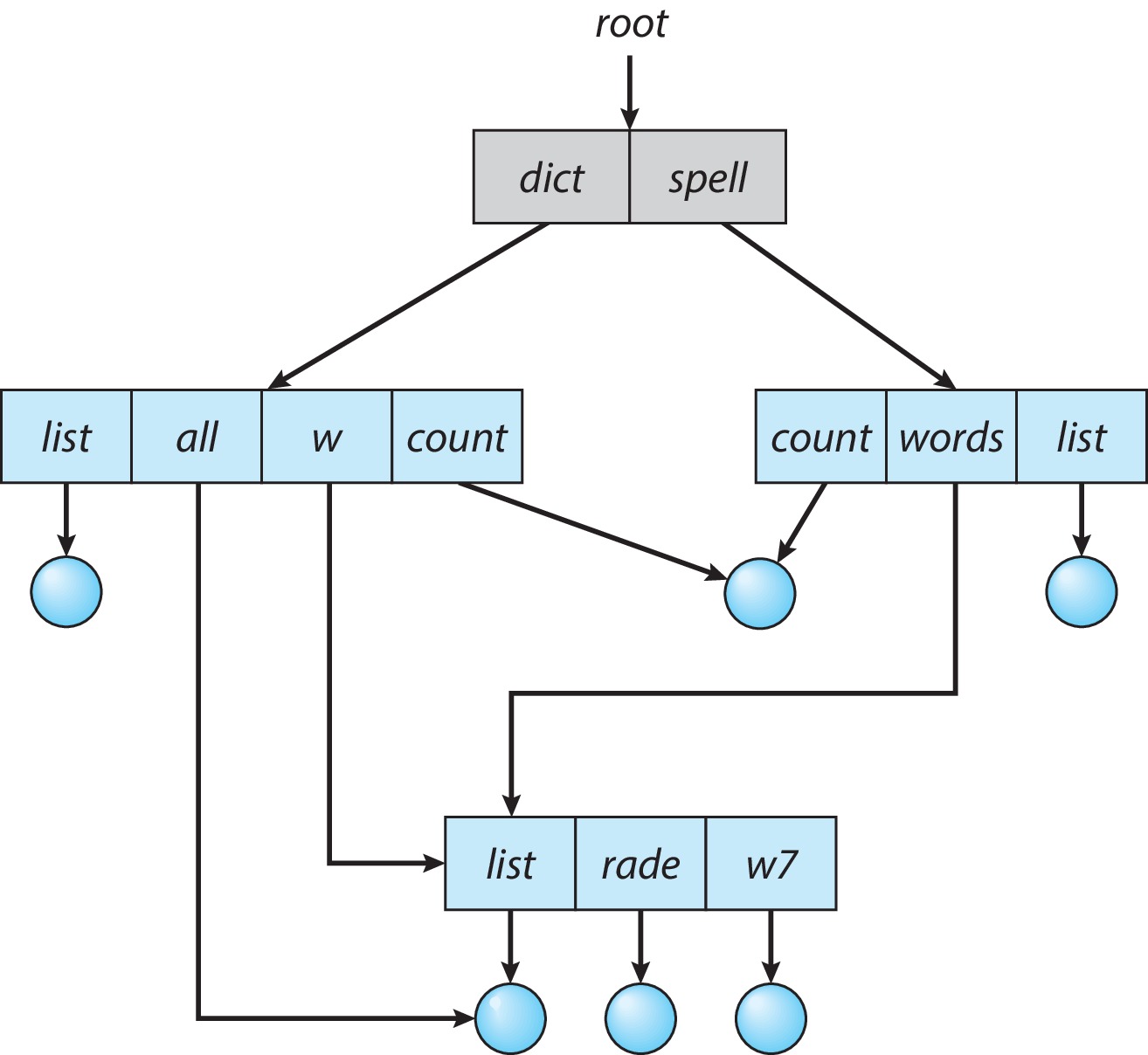
这种共享性有时候会用符号链接,也就是软连接实现,有时候也会通过硬链接实现。这两种不同的链接形式我们马上就会了解到。
3.2.5 General Graph Directory
在无环图目录结构中,目录不可以成”环“。然而这种环状目录在通用图目录结构中是允许的。环状目录或者成环其实就是目录中包含循环到起点的路径,即在下级目录中包含上级目录。
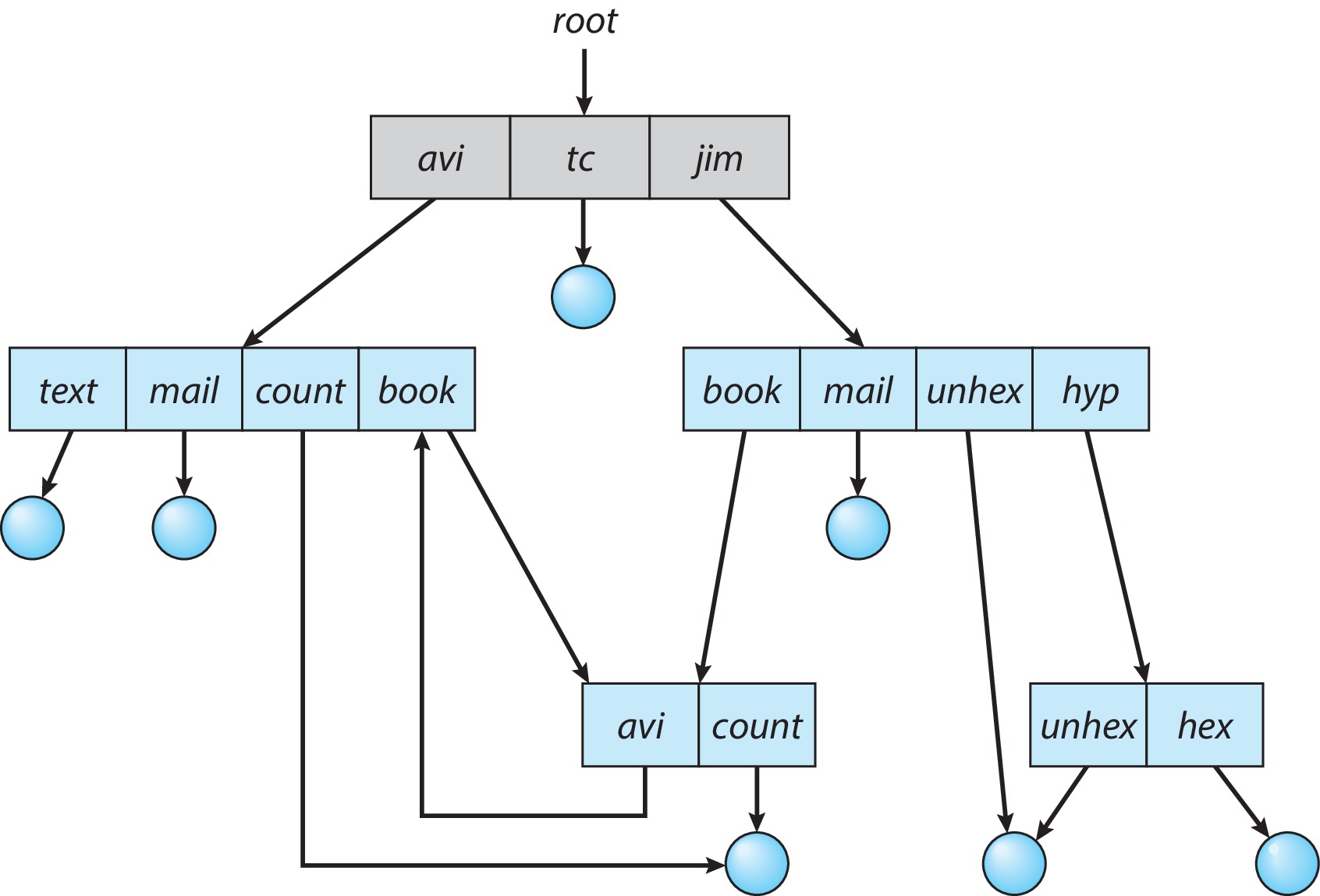
由于这种环状的存在,所以设计检索和遍历算法时就更加困难。这种环状可能导致遍历算法的无限循环,为了避免这种情况,设计者干脆禁止在目录中允许上级目录的存在。
3.3 Directory Implementation
3.3.1 AVL Tree
AVL树(AVL Tree)是目录实现中常见的数据结构。
3.3.2 B Tree
B树(B-Tree)极其变种也是目录实现中常见的数据结构。
3.4 Links
在文件系统中,硬链接是一个指向数据块的直接引用,出现在inode中。硬链接使得多个文件名指向相同的inode,因此它们共享相同的数据内容。
软链接是一种特殊的文件类型,出现在目录项中,它包含指向另一个文件路径的指针,而不是直接指向数据块。因此,软链接相当于文件的快捷方式。
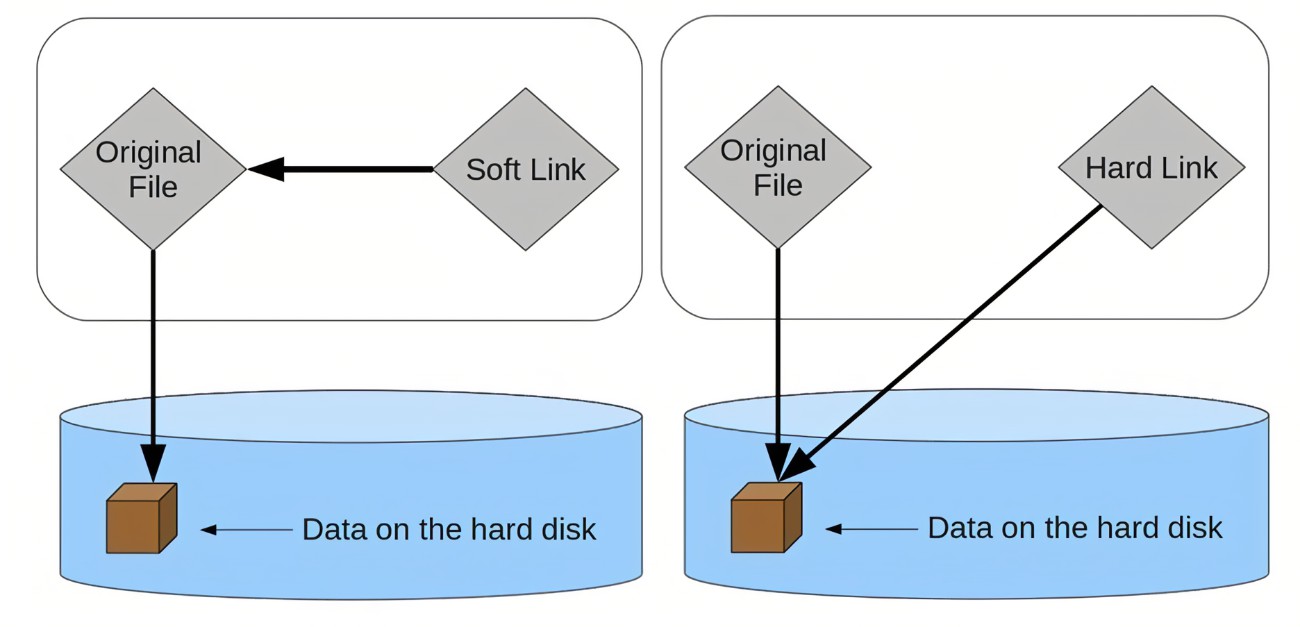
3.4.1 Hard Links
在Linux中,我们用命令ln来创建一个硬链接,例如:
du@du-virtual-machine:~/Desktop/OS$ ./Hello
Hello world
du@du-virtual-machine:~/Desktop/OS$ ln Hello Hard_Link
du@du-virtual-machine:~/Desktop/OS$ ./Hard_Link
Hello world
创建硬链接之后,两个文件会共享相同的inode(如上面例子中的Hello和Hard_Link)。也就是说它们会指向相同的数据内容。我们用stat命令查看Hello文件的元数据,可得:
du@du-virtual-machine:~/Desktop/OS$ stat Hello
File: Hello
Size: 15960 Blocks: 32 IO Block: 4096 regular file
Device: 803h/2051d Inode: 1049216 Links: 2
Access: (0775/-rwxrwxr-x) Uid: ( 1000/ du) Gid: ( 1000/ du)
Access: 2024-08-31 00:06:02.431095349 +0800
Modify: 2024-08-31 00:04:56.176093580 +0800
Change: 2024-08-31 00:05:46.451336108 +0800
Birth: 2024-08-31 00:04:56.128094303 +0800
du@du-virtual-machine:~/Desktop/OS$ stat Hard_Link
File: Hard_Link
Size: 15960 Blocks: 32 IO Block: 4096 regular file
Device: 803h/2051d Inode: 1049216 Links: 2
Access: (0775/-rwxrwxr-x) Uid: ( 1000/ du) Gid: ( 1000/ du)
Access: 2024-08-31 00:06:02.431095349 +0800
Modify: 2024-08-31 00:04:56.176093580 +0800
Change: 2024-08-31 00:05:46.451336108 +0800
Birth: 2024-08-31 00:04:56.128094303 +0800
我们看到,这两个文件名所指向的数据都是一样的。我们看到Links字段为2,这表示当前有两个目录项指向这个文件,也是文件的硬链接数。当硬链接数为0时,文件系统就会释放并回收文件资源。
3.4.2 Soft Links
我们用ln -s命令来创建一个软链接:
du@du-virtual-machine:~/Desktop/OS$ ln -s Hello Soft_Link
du@du-virtual-machine:~/Desktop/OS$ ./Soft_Link
Hello world
当软链接创建好后,软链接文件和源文件的inode并不相同。软链接本身是一个独立的文件,存储对源文件的路径引用。文件大小就是字符串的长度。我们用ls查看Soft_Link的大小,大小为5字节,正好是Hello文件名的长度。这里引用的是相对路径,但也可以引用绝对路径。
du@du-virtual-machine:~/Desktop/OS$ stat Soft_Link
File: Soft_Link -> Hello
Size: 5 Blocks: 0 IO Block: 4096 symbolic link
Device: 803h/2051d Inode: 1049994 Links: 1
Access: (0777/lrwxrwxrwx) Uid: ( 1000/ du) Gid: ( 1000/ du)
Access: 2024-08-31 00:43:40.242348874 +0800
Modify: 2024-08-31 00:43:40.238349935 +0800
Change: 2024-08-31 00:43:40.238349935 +0800
Birth: 2024-08-31 00:43:40.238349935 +0800
du@du-virtual-machine:~/Desktop/OS$ ls -l Soft_Link
lrwxrwxrwx 1 du du 5 8月 31 00:43 Soft_Link -> Hello
du@du-virtual-machine:~/Desktop/OS$ ls -l Hard_Link
-rwxrwxr-x 2 du du 15960 8月 31 00:04 Hard_Link
当源文件被删除,软链接就会指向一个不存在的路径。这时,软链接会变为无效链接,这就是“断链”现象。
第四课 File Allocation Methods
和内存的分配策略一样,文件系统在磁盘空间的利用上也有不同的分配方法。这节课我们将学习三种不同的分配方法,分别是contiguous、linked和indexed。但在此之前,我们先了解一下用户视角上的文件。
4.1 Logical Structure of a File
我们生活中的文件类型有很多种。您现在所看的算是一种线性的顺序结构,而当你看到这个系列,你可以直接点击阶段的大标题从而进入你想了解的阶段笔记进行学习,这是一种类似索引的结构。而在这个笔记中,我们有很多大标题小标题,这又可以看作是一种层次式的结构。在我们学习ELF文件时,文件中的数据又可以分段处理,这是一种分段式结构的文件。
文件的逻辑结构关注的是文件内容在用户视角下是如何组织的。即如何从软件层面组织和访问文件内容。上面提到过的四种逻辑结构有:
- 线性顺序结构/流式文件(Sequential Structure):文件内容按顺序存储和访问,一般用纯 ASCII、Unicode 编写的字符文档的内容是按线性顺序存储的(能够
cat的文件)。 - 索引结构(Indexed Structure):文件内容按索引表进行组织(如字典),索引表再指向实际数据的位置。索引结构允许快速定位到文件中某个特定数据上,常用于数据库文件或大型文件中,页表就是最常见的索引结构。
- 层次式结构(Hierarchical Structure):文件内部被组织成多级结构,每一级可以包含不同的数据段或子文件。层次化的逻辑结构有文件树形目录等。
- 分段结构(Segmented Structure):ELF 可执行文件就是这样分段的结构,文件中的内容被划分到各个独立的段中,每个段设置单独的属性分别管理。
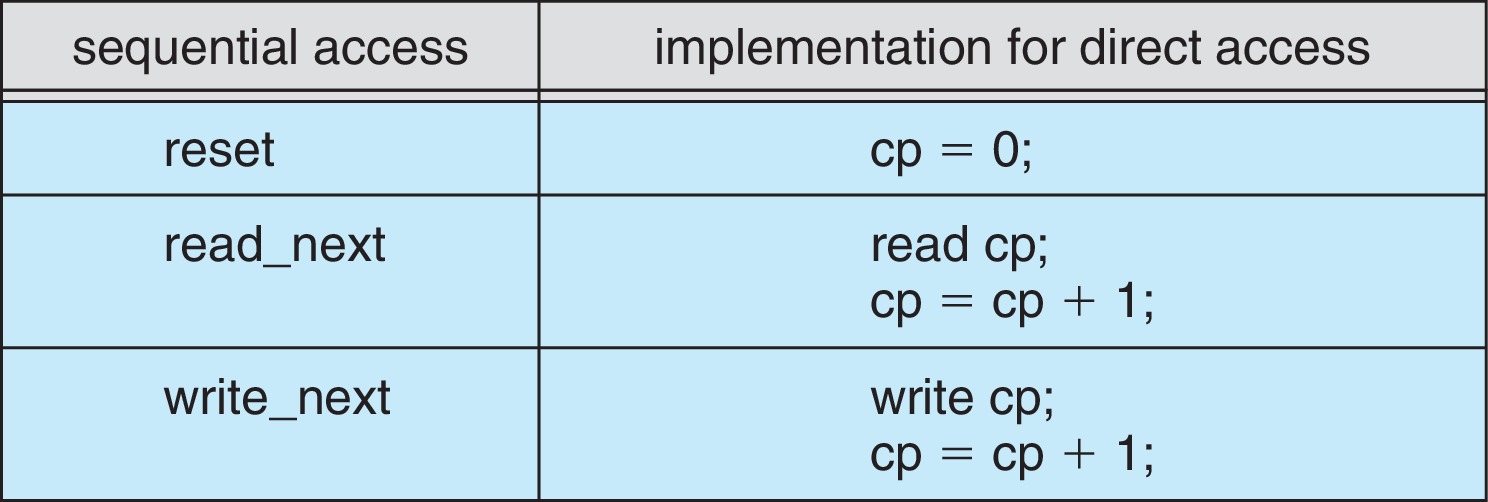
4.1.1 Sequential and Direct Access
我们看到的文件(即逻辑上的文件)主要有两种访问方式:顺序访问和随机访问(直接访问)。还有其他的访问方式都是在这两种访问方式的基础上建立的。
4.1.1.1 Sequential Access
顺序访问要求数据按照存储顺序从文件开头到结尾逐步读取或写入,你想看笔记的最有一小节时,你需要将笔记前面的内容全部加载到内存中。即便你只想要知道最后的内容,你也需要将文件整个加载。
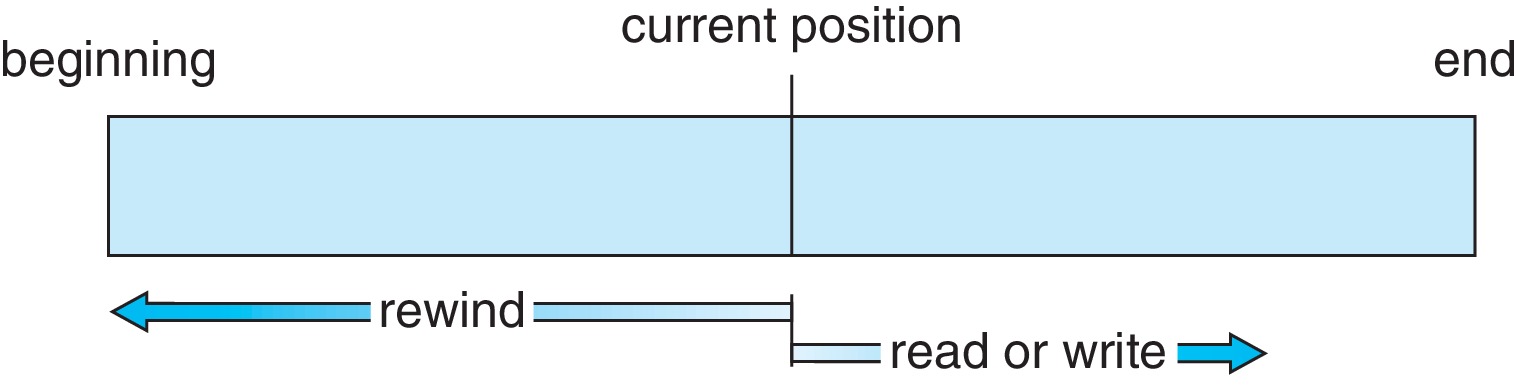
4.1.1.2 Direct Access
随机访问则允许直接跳转到文件中的任意位置进行读取或写入。由于文件内容可以非顺序处理,不需要将不需要的文件部分加载进内存,所以访问速度相较顺序访问要快。由于程序的局部性原理,在我们加载一些大型程序到内存中时,可能并不会将文件整个的加载进内存,这就是一种随机访问的文件访问方式。
4.1.2 Access Way of Different Logical File
我们前面提到了四种文件结构,对于这四种不太文件结构的文件而言,它们会遵循不同的访问方式。对于线性顺序结构的文件来说,由于要读取访问下一个字符数据必须先访问上一个字符数据。所以文件的访问必须是连续的,这不难理解。
对于索引结构的文件来说,索引表可以让我们访问文件的不同位置。然而,通过索引表跳转之后,文件的访问转而变成线性顺序的访问(宏观上跳转,微观上连续)。类似的,由于层次化的结构相当于多级索引,我们可以跳转到我们想要数据的最小目录下访问,这个访问是线性连续的。
对于分段结构的文件,我们可以将其理解成类索引的顺序结构文件。在 ELF 中,我们将文件中不同的内容划分到各个节中,这些段相当于独立的线性顺序结构的文件,但我们通过节头表定义并索引了文件中各个节的位置及属性。在 ELF 文件中,文件访问同样是节外跳转、节内连续。
4.2 Physical Allocation of a File
文件存放在持久性的存储设备上,文件的物理结构关注文件在硬盘、SSD等持久存储设备上的实际布局方式。文件的物理结构对于存储介质的特性、文件系统的实现密切相关(SSD可以随机存取;硬盘是随机存取+顺序存取;磁带只能顺序存取),主要包括以下几种形式:
- 连续分配(Contiguous Allocation)
- 链式分配(Linked Allocation)
- 索引分配(Indexed Allocation)
- 多级索引(Multilevel Index)
- 混合分配(Hybrid Allocation)
4.2.1 Contiguous Allocation
连续分配就是指文件占用一组连续的磁盘块。逻辑上相连的块在物理上也相邻。所以这种分配方式带来的好处就是当磁头读到的文件位于磁盘块b时,读取下一个文件块b+1时,磁头并不需要怎么移动,也就不存在寻道时间了(最小的寻道时间)。在这种分配方式下,磁盘的目录项包括:
- 文件名
- 第一个块的起始地址,块地址 = 扇区id(块大小 = 扇区大小)
- 文件长度(块长度)
即你只需要两个参数(起始块地址和文件长度)就能够keep track of this file。如果你需要读取 b+n 磁盘块中的内容,你只需要将磁头移动到相应的位置上,而不需要顺序一格一格地移动磁头,算是一种随机存取。这种方式可以轻易地实现对文件的顺序和直接访问。
而且这种方式在检查文件访问是否有效时非常简单,假设文件长度是 n,文件的起始块地址是 b。如果访问的磁盘块地址> b + n,那么就可以断定这个访问是不合法的。

享受完顺序分配给我们带来的简单性,我们就需要来承担相应的缺点。在顺序分配方式中,我们如果有一个大小为 N 个磁盘块的文件,在存储这个文件时,我们需要考虑:
- 磁盘分区中有没有这么大的空间能够被分配?
- 如果有,我们应该选哪个空间?
在磁盘空间动态分配时也可以选用不同的分配策略(首次适应、最佳适应、最差适应)。显而易见的是,这种分配方式会造成不可避免的外部碎片(external fragmentation),内部碎片(internal fragmentation)由于被控制在一个块的大小内,所以我们不需要注意。在这种分配方式下,如果文件很大,所有孔的容纳不下,那么文件将无法载入磁盘。
4.2.1.1 Contiguous Allocation and Compaction
除了要应对文件太大没有孔能够容纳这么大的文件之外,连续分配还给我们带来动态存储分配(dynamic storage allocation) 的问题。这是不可利用的外部碎片给连续分配方式带来的,这意味着大文件的扩展可能是很困难的。
对于外部碎片的处理,我们在内存分配的时候介绍过紧凑技术(compaction),那对于磁盘而言,通过移动磁盘块,将非空闲的磁盘块紧凑在一块,那将会为我们带来很大的一块空闲空间。然而,磁盘可比内存慢多了,这么做的代价将会非常大。(Disk defragmentation for more)
4.2.2 Linked Allocation
好,既然我们不确定文件有多大,也不想任何外部碎片的产生,我们为何不将文件块链式地存放在磁盘上呢?将文件进行分割成块,分配在多个离散的磁盘块中,通过指针连接。不会产生任何的外部碎片,而且文件扩展较为容易。如何?
顺序分配和链式分配的关系相当于数组和链表之间的关系。链式分配带来了诸多好处,其中最主要的就是避免了任何的外部碎片。但是由于需要指向下一个磁盘块的指针和不能随机访问的特性,使得链式分配方式会不可避免地占用一点空间用于存储指针,并且速度慢(存在寻道时间)。

链式分配方式的一大缺点就是当你要找一个文件块,你就必须得顺着指针链条往上找。所以一般的实现上,通常会结合连续分配和链式分配的优点。即以簇(clusters) 为单位进行连续分配,我们可以设置为4个块1个簇,然后将这些单位链接起来。这种方法可以提高访问速度,同时减少碎片问题。
4.2.3 Indexed Allocation
如果你是原始链式分配的原教旨主义者,你就会将自己困在无法随机访问带来的访问速度的困境中。然而,我们可以给每个文件建立索引表,把所有的指针都顺序地放在一个磁盘块中,记录文件各逻辑块对应的物理块。这样就可以实现随机访问文件了,吸收了顺序分配的优点;而且不会产生任何的外部碎片,同样结合了链式分配的优点。

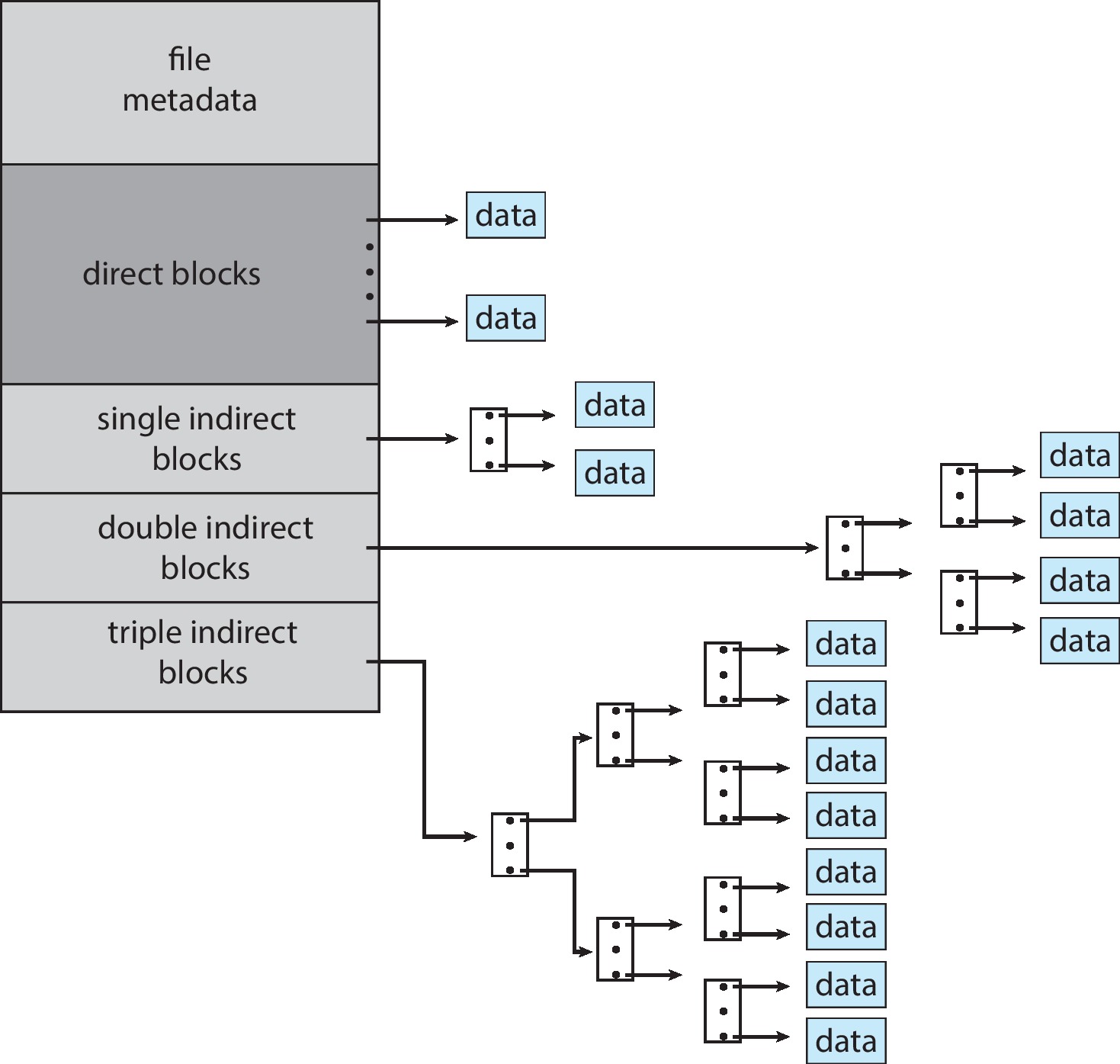
这种分配方式真不错,既保留了顺序连续分配的优点,也保留了链式分配的优点。但是有一点不足,即当文件变得很大,我们就没有办法对文件进行分配了,因为一个块能够索引的大小很有限。对于这种窘境,人们想出来很多办法。如:将index block最后一个index entry作为下一个index block的entry(linked scheme);加入上级的index对index block进行索引(multilevel index);将上述的方法结合起来,这也是inode所使用的方式(combined scheme)。
4.2.4 The Unix Inode
下图展示了unix inode的multilevel indexing,在本阶段后续的课程中我们会详细介绍。
4.2.5 Pre-Allocation
第五课 Disk Free Space Management
5.1 Free Space Management
我们学习了文件系统的设计。其中负责空闲空间管理的是文件组织模块/文件组织层。这个层次不单单负责逻辑块到物理块的转换,也负责逻辑上对磁盘存储块的管理,之后对逻辑块的管理进一步映射到物理块上。为了确保对磁盘的空闲空间能得到有效的利用,我们有许多对空闲空间管理的方法。我们接下来一个一个地介绍。
5.2 Bitmap/Bit Vector
位图是一连串比特位的集合。在位图法中,我们用一位bit代表一块磁盘块。Bit可以取0和1,因而我们用0表示空磁盘块,用1表示已使用磁盘块。如下的磁盘空间就可以用16bits的位图:1111 0001 1111 1001 来表示。

这种方式无论是理解还是实现都非常的简单。一个bit表示一个磁盘块,空间上也很划得来,利用率肯定不低。然而,如果我们暂时只能用磁盘很小一部分区域,位图法就会占有不该占有的内存空间。而且位图的大小是固定的,如果磁盘扩展,就需要重新初始化位图。
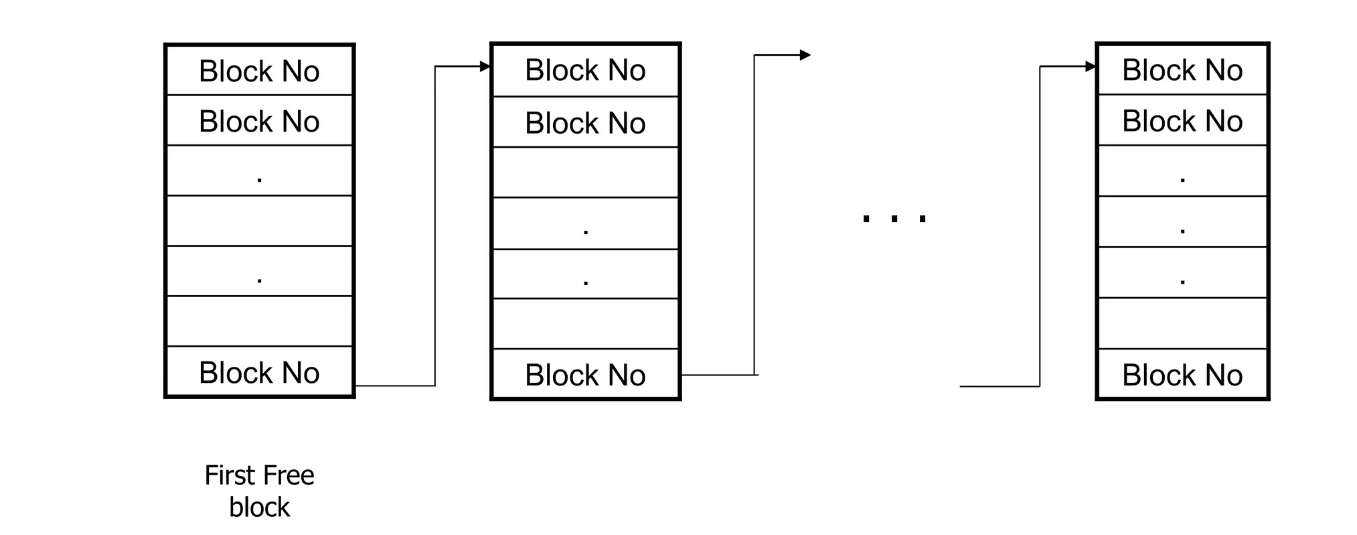
5.3 Linked List
为了扩充磁盘的便利,我们可以使用链表。空闲链表法的实现方式就是将所有空闲块用链表链接起来。空闲块中包含指向下一个空闲块的指针,在下图的实现中,空闲空间链接头指向 Block5,然后 Block5 的指针域指向 Block6 以此类推。

相比于位图法,空闲链表法的空间利用效率不会浪费其不该占用的内存空间。而且动态分配很容易,因而也可以动态的增加磁盘空间。但是指针动态分配的便利性也会造成该方法的指针维护很复杂,而且并不适合遍历。
5.4 Grouping
这是空闲链表法的变种。不同于空闲链表,在分块成组法中,每一个空闲块的地址存放在 n 个磁盘块中,通过将这 n 个磁盘块链接起来,我们就能够轻松的找到那些未分配的磁盘块了(相当于索引+链接)。这种方式看起来很不错,因为我们可以很轻松的分配一大片空闲磁盘块。但是缺点也很明显,每一次的分配都会使得整个列表重新修正整个list。
5.5 Counting
在counting的方法中,系统会用特定的格式(start base address, # numbers of free blocks)记录这些连续的空闲块。如果大多数连续空间块的长度超过了1块,那么这个列表将会非常紧凑。为了保证搜索、插入和删除的高效性,系统通常会用一个平衡树中存储这些记录。保证操作的效率。
5.6 Space Maps
5.7 TRIMing Unused Blocks
第六课 Different File Systems
6.1 FAT
文件分配表(File Allocation Table, FAT) 是链式分配的变种。最早由微软在1970年代为MS-DOS操作系统开发。由于简单的设计,FAT适用于各种各样的存储设备如软盘、硬盘、移动存储设备等。FAT采用簇链式存储分配,但簇中不再存放下一个簇的指针信息了,FAT会额外使用一块空间专门记录这些簇指针的信息,也就是FAT表,这也是FAT文件系统的特点和命名由来。
FAT早期版本包括 FAT12 和 FAT16,应用于存储容量较小的设备上,随着存储设备容量的不断增加,FAT32 被引入,用于支持更大的分区和文件大小。今天,NTFS代替了FAT作为Windows系统上应用的文件系统,但FAT32仍广泛应用在U盘上(兼容性佳)。
6.1.1 FAT Volume Structure Layout
FAT文件系统下,磁盘结构被划分成引导扇区、文件分配表FAT、根目录区和数据区域。我们接下来逐步介绍。
6.1.1.1 Boot Sector
作为磁盘分区的开始,为了保证计算机的正常启动,传统的,我们将第一个扇区作为引导扇区使用(第二个扇区可能会作为冗余对引导扇区进行备份)。引导扇区包括我们介绍过的启动代码和磁盘参数块(disk parameter block),在磁盘参数块中包含磁盘的信息和文件系统的基本信息。
磁盘信息有:每个扇区多少字节、每个track几个扇区、磁头信息等。文件系统的信息有:FAT表数量、每个FAT表的扇区数、根目录项的数量、簇的信息等。
6.1.1.2 FAT
在引导扇区之后,作为FAT的重中之重,我们通常会看到两个相同的FAT表用于冗余和数据的恢复。每个FAT表都记录了磁盘上所有簇的状态和链表信息。FAT表是一个数组,其中的每个元素对应磁盘中的一个簇,元素的数值代表了该簇的状态:
- 值为0:簇空闲(空闲空间管理)
- 值为正整数:簇已被占用,其中的数字指示下一个簇的编号
- 值为EOF(-1):文件结尾

通过把这些指针信息整合到一块,实际上FAT会比传统的簇链式方式要快很多。因为操作系统可以将整个FAT都加入到内存中(FAT不会很大),避免了对I/O的重复访问。
6.1.1.3 Root Directory
根目录区域(Root Directory):存储文件和目录的目录项信息,包含文件名、扩展名、属性、创建时间、起始簇号等。
6.1.1.4 File and Directiory Area
之后的一大片空闲的磁盘块就都用来作为数据区域(File and Directory Area)。这个区域存放文件和目录的数据内容。文件的数据被分配到多个簇中,簇之间通过FAT表链接。
6.1.2 File Maxium Capacity in FAT
我们常常会看到FAT16/FAT32,FAT后面的数字代表什么呢?这代表着FAT表中表项的位数,即FAT能够寻址的簇数。通过这个信息和簇大小信息,我们就可以得到最大分区大小是多大了。文件大小根据目录表项(FCB)中文件大小字段的位数决定。
6.1.2.1 FAT16
FAT16的FAT表项是16bits,代表着每个表项可以表示
6.1.2.2 FAT32
同样,在FAT32中,FAT表项是32bits,但是实际上用于表示簇的有效位只有28位,其余的位数用来标记EOF和保留位。其余部分和FAT16相同的情况下,最大分区大小为:
6.1.2.3 We've Got a lot of FAT
我们现在能够明白FAT文件系统分区大小和单文件大小限制的因素有哪些,并且是如何影响FAT最大分区大小和最大文件大小的。然而FAT变种有很多,因此FAT16/32的最大文件大小或最大分区大小并不是固定的。根据不同的实现方式,所得出来的结果也是不一样的。
6.2 The Second Extended File System (ext2)
扩展文件系统是Linux系统中常见的文件系统,ext系统算是一种类UNIX文件系统的文件系统,ext的出现就是为了克服MINIX文件系统的一些缺点。在ext文件系统中的块(blocks)、索引节点(inodes) 和目录和一些文件所有权/访问权限(ownership/access)、链接(symbolic/hard links) 等都是继承传统UNIX文件系统的概念。
ext2是原始版本ext的重写,这些类UNIX文件系统的ext特点就是作为核心地位的“inode”。Ext2文件系统在1990年代初到2000年代初的近十年间,作为Linux的文件系统被广泛使用。后来,它被支持日志功能的文件系统ext3和ReiserFS所取代。
6.2.1 Blocks
在ext2文件系统中,磁盘空间被划分为连续的逻辑块(blocks)。块大小并不需要与磁盘的物理扇区大小相同,因此块的大小还能更大,以便优化文件系统的性能和数据管理效率。在ext文件系统中,超级块负责卷空间信息的记录和管理。块大小由超级块中特定的字段所设置。
块大小一般会设置为是1024字节、2048字节或4096字节(ext2中块最大可以设置为65536个字节)。一旦文件系统初始化完成,块大小就将固定。块大小越小,存储文件产生的存储碎片就越少,但是相应地就会带来额外的管理开销(而且文件大小和文件系统大小就越小)。当前,主流的默认块大小是4KB。
6.2.2 Block Groups
块组是许多个块聚合在一起所构成的。磁盘空间被划分成了若干个块组,这样组织有效的避免了文件分散在磁盘的各个位置,从而减小了磁头的寻道时间;同时,也对碎片化有重要的影响。除此之外,块组中包含有一些重要数据的备份(如超级块等),使得文件系统能够在必要的时刻重建。
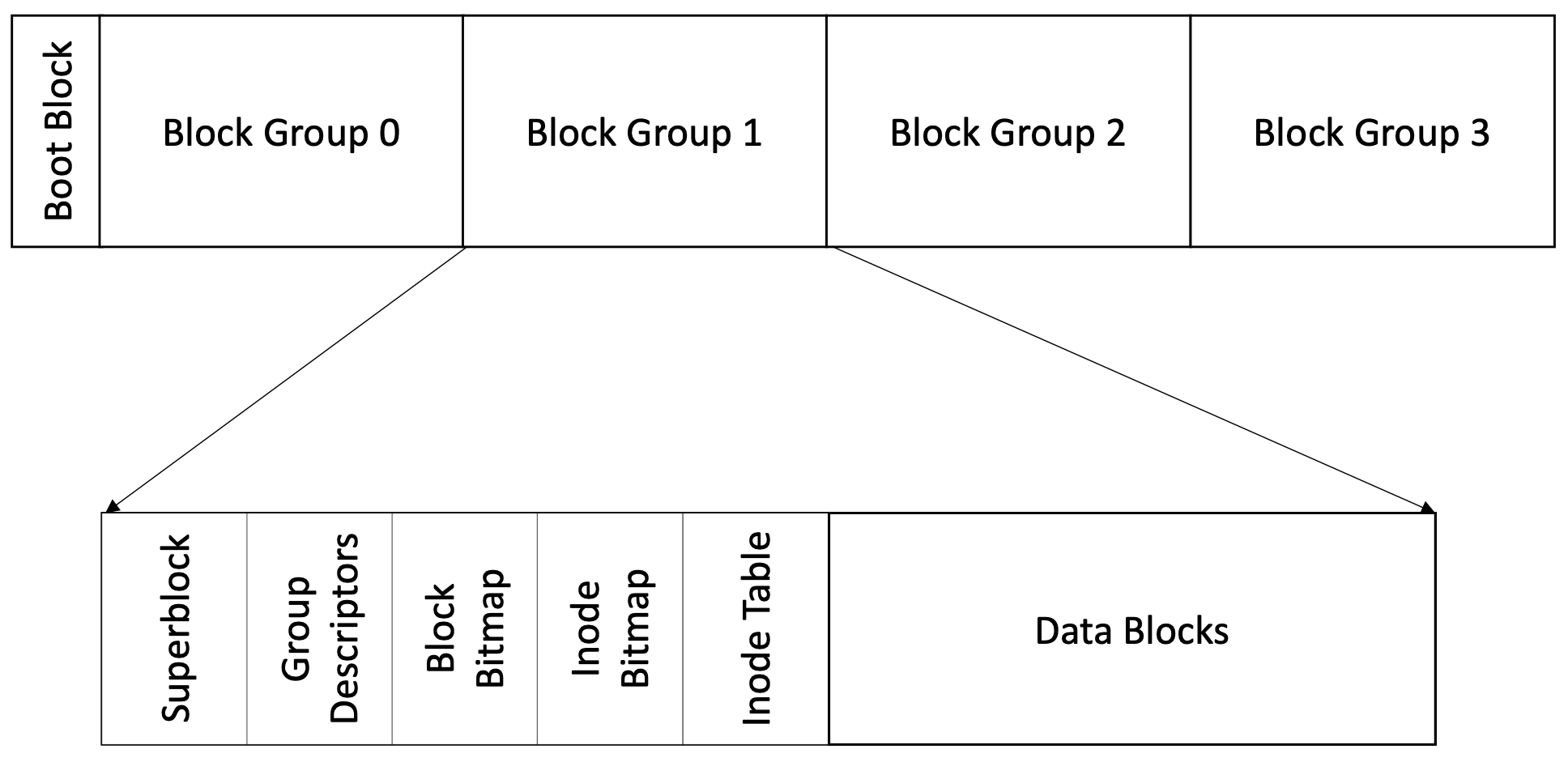
磁盘被划分为若干个块组。每个块组由一定数量的块(Blocks)构成,包含:超级区块(Super Block)、组描述符表(Group Descriptor Table)、区块位图(Block Bitmap)、索引节点位图(Inode Bitmap)、索引节点表(Inode Table)、数据块区(Data Blocks)。
当一个文件的数据量超过一个块组的容量时,文件的数据块会分布在多个块组中。inode中的块指针可以指向不同块组中的数据块,从而实现跨块组的存储。一般而言,块组描述符表还会有一个备份,一个标准的块组0磁盘布局如下(N>>n):
| Group 0 Padding | Super Block | Group Descriptors | Reserved GDT Blocks | Data Block Bitmap | inode Bitmap | inode Table | Data Blocks |
|---|---|---|---|---|---|---|---|
| 1024 字节 | 1 个块 | n 个块 | n 个块 | 1 个块 | 1 个块 | n 个块 | N 个块 |
6.2.2.1 Group Descriptor Table
块组描述符表存储每个块组的基本信息,如inode表的起始块号、空闲块位图的起始块号等。
6.2.2.2 inode Table and Data Blocks
如果块大小是4KB,那么数据块位图和inode位图就能够表示
上面这些是理论值的计算,实际上,我们可以设置inode和块数存在一定的对应关系。比方说一个块组中最多存放32个文件,那么inode表就只需要4KB的磁盘空间。
6.2.3 The Superblock
ext2文件系统所有核心配置信息都存储在超级块中,它包含了如文件系统中的inode总数、块总数、块大小、空闲块和空闲inode数量等信息,对于文件系统的正常运行和管理至关重要。超级块位于卷偏移1024字节后(boot loader之后),由于超级块的重要性,在最初的ext2版本中,每个块组中都会留有超级块的备份。之后的版本将组号为0、1还有奇数的平方作为超级块的备份块组使用。
ext2文件系统的超级块以小端方式存放在磁盘上,所以文件系统在不同机器上是可移植的。
6.2.3.1 Superblock Data Structure
struct ext2_super_block {
__le32 s_inodes_count; /* Inodes count */
__le32 s_blocks_count; /* Blocks count */
__le32 s_r_blocks_count; /* Reserved blocks count */
__le32 s_free_blocks_count; /* Free blocks count */
__le32 s_free_inodes_count; /* Free inodes count */
__le32 s_first_data_block; /* First Data Block */
__le32 s_log_block_size; /* Block size */
__le32 s_log_frag_size; /* Fragment size */
__le32 s_blocks_per_group; /* # Blocks per group */
__le32 s_frags_per_group; /* # Fragments per group */
__le32 s_inodes_per_group; /* # Inodes per group */
__le32 s_mtime; /* Mount time */
__le32 s_wtime; /* Write time */
__le16 s_mnt_count; /* Mount count */
__le16 s_max_mnt_count; /* Maximal mount count */
__le16 s_magic; /* Magic signature */
__le16 s_state; /* File system state */
__le16 s_errors; /* Behaviour when detecting errors */
__le16 s_minor_rev_level; /* minor revision level */
__le32 s_lastcheck; /* time of last check */
__le32 s_checkinterval; /* max. time between checks */
__le32 s_creator_os; /* OS */
__le32 s_rev_level; /* Revision level */
__le16 s_def_resuid; /* Default uid for reserved blocks */
__le16 s_def_resgid; /* Default gid for reserved blocks */
/*
* These fields are for EXT2_DYNAMIC_REV superblocks only.
*
* Note: the difference between the compatible feature set and
* the incompatible feature set is that if there is a bit set
* in the incompatible feature set that the kernel doesn't
* know about, it should refuse to mount the filesystem.
*
* e2fsck's requirements are more strict; if it doesn't know
* about a feature in either the compatible or incompatible
* feature set, it must abort and not try to meddle with
* things it doesn't understand...
*/
__le32 s_first_ino; /* First non-reserved inode */
__le16 s_inode_size; /* size of inode structure */
__le16 s_block_group_nr; /* block group # of this superblock */
__le32 s_feature_compat; /* compatible feature set */
__le32 s_feature_incompat; /* incompatible feature set */
__le32 s_feature_ro_compat; /* readonly-compatible feature set */
__u8 s_uuid[16]; /* 128-bit uuid for volume */
char s_volume_name[16]; /* volume name */
char s_last_mounted[64]; /* directory where last mounted */
__le32 s_algorithm_usage_bitmap; /* For compression */
/*
* Performance hints. Directory preallocation should only
* happen if the EXT2_COMPAT_PREALLOC flag is on.
*/
__u8 s_prealloc_blocks; /* Nr of blocks to try to preallocate*/
__u8 s_prealloc_dir_blocks; /* Nr to preallocate for dirs */
__u16 s_padding1;
/*
* Journaling support valid if EXT3_FEATURE_COMPAT_HAS_JOURNAL set.
*/
__u8 s_journal_uuid[16]; /* uuid of journal superblock */
__u32 s_journal_inum; /* inode number of journal file */
__u32 s_journal_dev; /* device number of journal file */
__u32 s_last_orphan; /* start of list of inodes to delete */
__u32 s_hash_seed[4]; /* HTREE hash seed */
__u8 s_def_hash_version; /* Default hash version to use */
__u8 s_reserved_char_pad;
__u16 s_reserved_word_pad;
__le32 s_default_mount_opts;
__le32 s_first_meta_bg; /* First metablock block group */
__u32 s_reserved[190]; /* Padding to the end of the block */
};
6.2.4 Index Nodes
Inode是ext2文件系统中的一个重要概念。Inode本质上是文件控制块,任何在ext2文件系统上的对象都需要用inode来表示,如文件、目录、符号链接等。inode中包含着除了文件名以外的所有文件元数据,如文件的权限(permissions)、所有者、组、flags、大小、使用的块数、访问创建修改删除时间、链接数、ACLs等。
每个块组都有一个线性数组来存储inode节点数据,这个数组被称为 inode table。在ext2/3中,每个inode需要128KB的存储。每个inode都属于一个特定的块组,并存储在相应的 inode table 中。
6.2.4.1 inode Data Structure
ext2/3的inode数据结构占用128个字节,ext4扩展为256个字节。以下是ext2/3的inode数据结构:
| Offset | Size | Field Name | Description |
|---|---|---|---|
| 0 | 2 | i_mode | 文件类型和权限 |
| 2 | 2 | i_uid | 低16位的用户ID |
| 4 | 4 | i_size | 文件大小(字节) |
| 8 | 4 | i_atime | 最后访问时间 |
| 12 | 4 | i_ctime | inode创建时间 |
| 16 | 4 | i_mtime | 最后修改时间 |
| 20 | 4 | i_dtime | 删除时间 |
| 24 | 2 | i_gid | 低16位的组ID |
| 26 | 2 | i_links_count | 硬链接计数 |
| 28 | 4 | i_blocks | 文件占用的块数 |
| 32 | 4 | i_flags | 文件标志 |
| 36 | 4 | osd1 | 操作系统依赖字段1 |
| 40 | 60 | i_block[EXT2_N_BLOCKS] | 数据块指针(直接、间接、双级间接、三级间接) |
| 100 | 4 | i_generation | 文件版本(用于NFS) |
| 104 | 4 | i_file_acl | 文件访问控制列表 |
| 108 | 4 | i_dir_acl | 目录访问控制列表 |
| 112 | 4 | i_faddr | 碎片地址 |
| 116 | 12 | osd2 | 操作系统依赖字段2 |
在ext2/3的inode数据结构中,最高的16bits数据用来表示类型和权限(Type and Permission)。其中 higher 4 bits 用来表示文件的类型,如:
| Type value in hex | Description |
|---|---|
| 0x1000 | FIFO |
| 0x2000 | Character device |
| 0x4000 | Directory |
| 0x6000 | Block device |
| 0x8000 | Regular file |
| 0xA000 | Symbolic link |
| 0xC000 | Unix socket |
Lower 12 bits are used to present file permission as following below:
| Type value in binary | Description |
|---|---|
| 000 000 000 001 | Execute (Others) |
| 000 000 000 010 | Write (Others) |
| 000 000 000 100 | Read (Others) |
| 000 000 001 000 | Execute (Group) |
| 000 000 010 000 | Write (Group) |
| 000 000 100 000 | Read (Group) |
| 000 001 000 000 | Execute (Owner) |
| 000 010 000 000 | Write (Owner) |
| 000 100 000 000 | Read (Owner) |
| 001 000 000 000 | Sticky bit |
| 010 000 000 000 | Set GID |
| 100 000 000 000 | Set UID |
我们用ls -alh命令就会看到相关的i_mode信息,如:
du@du-virtual-machine:~/Desktop/OS$ ls -alh
total 136K
drwxrwxr-x 3 du du 4.0K 8月 30 02:05 .
drwxr-xr-x 7 du du 4.0K 8月 8 05:09 ..
drwxrwxr-x 2 du du 4.0K 7月 1 00:51 critical_section
-rwxrwxr-x 1 du du 17K 7月 2 13:50 mutex
-rw-rw-r-- 1 du du 1.2K 7月 2 13:50 Mutex_locks.c
......
6.2.4.2 Indexing Inode
inode本身并不存储数据信息,其会通过存放指向数据块的索引表来引用文件的实际内容。通常情况下,一个inode对应一个文件或目录,但通过硬链接,可以有多个文件名指向同一个inode。
索引文件数据块是inode最重要的功能,inode也因此得名(index-node)。inode通过一张索引表来索引文件文件块,这个索引表有15个字段,每个字段4字节,共60字节。记录了指向一个数据块的指针。其中有直接块(direct block)、单级间接块(single indirect)、双级间接块(double indirect)、三级间接块(triple indirect)。

- 直接块指针:每个inode包含12个直接块指针,直接块指针直接指向一个数据块。
- 单级间接块指针:一个单级间接块指针指向一个间接块表,间接块表中包含指向数据块的指针。若一个块4KB,每个指针大小为4字节,那么一个间接块表可以包含1024个直接块指针。
- 双级间接块指针:一个双级间接块指针指向一个间接块表,间接块表中的每个指针又指向另一个间接块表。这样可以寻址更多的数据块。
- 三级间接块指针:一个三级间接块指针指向一个间接块表,间接块表中的每个指针指向另一个间接块表,依次类推,直到最终指向数据块。
6.2.4.3 Calculating Maximum File Storage
通过多级间接寻址方式,ext2文件系统理论上能够在32位系统上支持高达4TB的文件大小。具体计算如下,假如一个块的大小为4KB:
- 直接块:12个块
- 单级间接块:1024个块
- 双级间接块:1024 * 1024个块
- 三级间接块:1024 1024 1024个块
总共可以寻址的块数为:
然而,实际上文件大小限制还要收到文件系统实现和内核的限制。根据相关的Linux文档,当块大小为1KB时,单个文件大小限制在16GB,2KB的块为256GB的文件大小限制,块大小更大时,单个文件最大大小为2TB。
6.2.5 Dirctories
在ext2文件系统中,目录也是以文件的形式存储在磁盘上的,目录文件的文件控制块(FCB)也是一个inode。在目录文件中包括许多目录项(Entry),文件名和其inode编号就存放在目录项中,通过这一对文件信息可以检索到某一个文件。这些目录项使得操作系统可以通过文件名查找到对于文件的inode,进而访问文件的元数据和实际内容。目录项包含以下内容:
| Size in Bytes | Field Description |
|---|---|
| 4 | Inode |
| 2 | Total size of this entry |
| 1 | Name length |
| 1 | Type indicator |
| N | Name character |
其中文件类型有以下几种:
| Value | Type Description |
|---|---|
| 0 | Reserved |
| 1 | Regular file |
| 2 | Directory |
| 3 | Character device |
| 4 | Block device |
| 5 | FIFO pipe file |
| 6 | Socket |
| 7 | Symbolic link(Soft link) |
ext2文件系统用单链表来存储目录中的文件名;在改进后的版本中,使用文件名的哈希值来进行查找,免去了对整个文件目录的扫描。
6.2.5.1 How Do You Get a inode
- 通过文件名获取inode编号:使用目录项(directory entry)查找文件名对应的inode编号。
- 读取超级块:获取文件系统的基本信息,包括每个块的大小、每个块组中的块数量、每个块组中的inode数量以及块组描述符表的起始块位置。
- 确定inode所属的块组:根据inode编号和每个块组中的inode数量,计算出inode所属的块组。
- 读取块组描述符:读取对应块组的块组描述符,获取该块组的详细信息。
- 提取inode表的位置:从块组描述符中提取该块组的inode表的起始位置。
- 确定inode在inode表中的索引位置:根据inode编号和inode表的起始位置,计算出inode在inode表中的具体位置。
- 读取指定的inode:通过索引inode表,读取出指定的inode,获取文件的元数据和指向数据块的指针。
6.2.6 Consistency Check (e2fsck)
第七课 Concurrency in File Systems
通过第六课的学习,我们已经对inode有了一定的认识,inode是类Unix系统中用于表示文件的数据结构。Inode意为索引节点,通过inode,我们可以对文件数据进行索引,这是inode的两个最主要的作用。如果有多个进程想要并发地使用同一个文件,我们该怎么做?我们先从文件锁开始介绍。
7.1 File Locking
对一个文件的读写实际上就是我们在之前在同步问题中学到的读者写者问题。当文件打开时,程序会获得该文件的引用。如果你不想其他的应用程序使用文件,防止数据竞争和不一致问题,我们就可以将文件给锁起来。我们用fcntl系统调用来实现文件锁。
7.1.1 This is All Mine
POSIX有个系统调用flock(),我们可以用它来对文件进行加锁。下面实现了一个对文件的互斥锁(一个写锁)。flock()有两个字段,第二个属性字段除了LOCK_EX之外,还有LOCK_SH用于设置一个共享的锁、LOCK_UN对锁进行解锁。
#include <stdio.h>
#include <sys/file.h>
FILE* f = fopen("example.txt", "r");
int fd = fileno(f);
int result = flock(fd, LOCK_EX);
flock()的函数原型如下:
#include <sys/file.h>
int flock(int fd, int operation);
/* Parameters:
1. fd: File descriptor of the file to be locked.
2. operation: Operation to be performed (e.g., LOCK_SH for shared lock, LOCK_EX for exclusive lock, LOCK_UN for unlocking).
Return value: Returns 0 on success, otherwise -1.
*/
这种写锁(LOCK_EX)只允许一个进程访问文件,对整个文件都进行了加锁。如此,其他进程不能读写该文件,如果我们想要对文件进行粒度更细的管理怎么办?我们可以使用POSIX提供的fctnl系统调用。
7.1.2 Me Get My Share
fcntl() 提供了更复杂和灵活的文件锁定机制,支持对文件的部分区域进行锁定。通常情况下,部分锁定(partial locking)也会被称为记录锁定(record locking)。我们常常在data record中看到这种记录锁定。我们现在其实并不怎么使用这种部分锁定,因为有数据库在背后帮我们处理这些事情。
通过将文件划分成多个部分,例如6个部分,我们最多可以同时有6个程序对文件进行读写操作。fcntl()是一个强大的系统调用,命令字段实际上有很多参数信息。我们在这里只讨论关于文件锁的部分信息。以下是 fcntl() 的原型:
#include <fcntl.h>
int fcntl(int fd, int cmd, ... /* struct flock *lock */);
/* Parameters:
1. fd: File descriptor of the file to be locked.
2. cmd: Command to be performed. Common file locking commands include:
- F_GETLK: Get record locking information.
- F_SETLK: Set record locking information (non-blocking).
- F_SETLKW: Set record locking information (blocking).
3. lock: Pointer to a struct flock that specifies the lock parameters (used with F_GETLK, F_SETLK, and F_SETLKW).
Return value: Returns 0 on success, otherwise -1.
*/
7.1.2.1 Struct flock
这个系统调用的第一个参数是文件描述符,第二个参数是一些关于文件锁的一些命令,第三个参数是一个指向flock结构体的指针,这个结构体如下,这些字段并不难理解:
struct flock {
short l_type; // F_RDLCK, F_WRLCK, F_UNLCK
short l_whence; // SEEK_SET, SEEK_CUR, SEEK_END
off_t l_start; // offsets in bytes, relative to l_whence
off_t l_len; // length in bytes; 0 means lock to EOF
pid_t l_pid; // returned lock owner's PID with F_GETLK, otherwise return 0
}
通过设置l_len字段,我们事实上可以将整个文件区域进行锁定,我们需要设置l_len = 0;
7.1.2.2 Да, Comrade!
下面,我们来看fcntl的第二个参数。和文件锁相关的有三个命令,第一个命令F_GETLK就是检查指定的区域是否被其他进程所锁定。如果被锁定,那将把l_type设置为不同的锁类型并在l_pid字段返回持有锁进程的ID,如果没有被锁定,那就会将l_type设置为F_UNLCK。但是这个命令作用并不大,因为F_GETLK的检查并不是原子化的(我们检查时可能发生状态变化)。
下面的两个命令F_SETLK和F_SETLKW(set lock wait),两个命令的作用实际上非常相似,只是阻塞和非阻塞的区别。F_SETLK会尝试设置指定的锁定区域。如果锁定区域被其他进程锁定,调用将失败并返回 -1,并不会等待区域变为可用(和try_lock很像);而F_SETLKW会在检查到区域锁定后阻塞并等待,直到锁定区域变为可用或接收到一个信号中断。
在应用中,我们并不会先检查指定区域是否可用后将区域锁定,而是通过F_SETLK的方式设置锁,如果当前程序可以等,那就将其阻塞,使用F_SETLKW确保程序后续能够将区域锁定。
7.1.2.3 Lock Unlock Example
int write_lock_file(int fd) {
struct flock fl;
fl.l_type = F_WRLOCK;
fl.l_start = 0;
fl.l_whence = SEEK_SET;
fl.l_len = 0; // Lock the entire file due to l_len = 0
return fcntl(fd, F_SETLK, &fl);
}
int unlock_file(int fd) {
struct flock fl;
fl.l_type = F_UNLOCK;
fl.l_start = 0;
fl.l_whence = SEEK_SET;
fl.l_len = 0; // Unlock the entire file
return fcntl(fd, F_SETLK, &fl);
}
Lock the part of the file:
int fd = open("example.txt", O_RDONLY);
struct flock fl;
fl.l_type = F_RDLOCK;
fl.l_start = 1024;
fl.l_whence = SEEK_SET;
fl.l_len = 256;
fcntl(fd, F_GETLK, &fl);
if(fl.l_type == F_UNLCK){
// Lock is unlocked, we may proceed.
}
else if(fl.l_type == F_WRLOCK){
printf("File is locked by process ID %d.\n", fl.l_pid);
return -1;
}
7.1.3.4 Be Aware
使用fcntl有两个缺点,那就是你要用重用结构体的话那就需要将结构体reset,你还需要确保字段的正确设置;此外,代码的逻辑需要额外地注意,当F_SETLK返回-1时,后续的逻辑流就不能够再出现相关F_UNLOCK的操作。
7.1.3 lockf IS NOT flock
如果你不想让文件锁定操作那样复杂,那你可以使用lockf系统调用。在一些系统上,lockf是由fcntl系统调用封装而来的,但有的系统可能使用其他的机制。所以当你lock a file时,确保使用同样的系统调用来lock and unlock,避免可能出现的一些未定义行为。
#include <unistd.h>
int lockf(int fd, int command, off_t length);
/*
Parameters:
1. fd: File descriptor of the file to be locked.
2. command: Command to be performed. Common commands include:
- F_LOCK: Lock a section of the file.(blocking)
- F_TLOCK: Try to lock a section of the file (non-blocking).
- F_ULOCK: Unlock a section of the file.
- F_TEST: Test a section of the file for locks held by other processes.
3. length: Length of the section to be locked, in bytes. A value of 0 means to lock from the current position to the end of the file.
Return value: Returns 0 on success, otherwise -1.
*/
7.1.4 Advisor Locks and Mandatory Locks
mandatory locks do exist,but are hard to use and not recommended
7.1.5 Using File as a Lock
除了上述我们学习过的这些文件锁,我们可以用文件来控制文件的并发访问。将一个文件的存在当作一把锁,如果文件存在,则说明区域已被锁定。Git会通过在特定的目录处放置一个index.lock的文件来指示进行中的操作。通过这个文件,git就能避免多个git客户端同时操作一个repo。
为了实现这种机制,我们可以使用以下的系统调用:
int open(const char *pathname, int flags);
int rename(const char* old_filename, const char* new_filename);
int remove(const char* filename);
open系统调用有许多选项,在这种情形下,我们并不想使用”如果文件存在,则打开文件“的open系统调用。我们想要系统告诉我们:”如果文件存在,则创建失败并返回错误码“。所以我们要用O_CREAT和O_EXCL这两个flags。前者是创建文件,后者是exclusive的缩写,当两个一起使用时,就会在文件存时返回失败并设置errno为EEXIST。
用于open系统调用是原子化的,所以实际上避免了多个进程的并发问题。在操作完成后,我们用remove系统调用来删除文件,让下一个用户进程对文件或repo进行操作。
那rename系统调用是做什么的?rename系统调用和open一样,也是原子化的。这样,我们其实可以单单用rename来进行lock和unlock操作。改名就是锁定,解锁呢,就是将文件名改回来。
7.2 Concurrency in VCS
前面我们介绍了如何用文件作为锁来控制并发。在版本控制系统中,我们常常会看到两种不同的并发控制策略,分别是Lock-Modify-Unlock 和 Copy-Modify-Merge(也称为 Lock-Modify-Merge),它们在不同的场景下被使用。
7.2.1 Lock-Modify-Unlock
Lock-Modify-Unlock常会用在集中式的版本控制系统中。在开发者修改文件之前,首先锁定文件,防止其他人同时修改(lock);之后,开发者对文件进行修改(modify);完成后解锁文件,运行其他人对文件进行修改(unlock)。以下是我们用文件作为锁对这种方式的简单实现:
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <pthread.h>
#define NUM_THREADS 10
int lock_fd;
int shared = 0;
void* run(void* arg){
int* id = (int*) arg;
while(rename("file.lock", "file.unlock") == -1){ // Lock the lock
// thread is waiting.
}
// thread in critical section
printf("Thread %d is in the critical section.\n", *id);
printf("Shared incremented from %d", shared);
shared++;
printf(" to %d.\n", shared);
rename("file.unlock", "file.lock"); // Unlock the lock.
free(arg);
pthread_exit(NULL);
}
void* writer(void* arg){
/* Write data implementation not shown*/
pthread_exit(NULL);
}
int main(int argc, char** argv){
lock_fd = open("file.lock", O_CREAT | O_EXCL, 0644);
if(lock_fd == -1){
printf("File creation failed.\n");
return -1;
}
pthread_t threads[NUM_THREADS];
for(int i = 0; i < NUM_THREADS; i++){
int* id = malloc(sizeof(int));
*id = i;
pthread_create(&threads[i], NULL, run, id);
}
for(int i = 0; i < NUM_THREADS; i++){
pthread_join(threads[i], NULL);
}
close(lock_fd);
remove("file.lock");
return 0;
}
这种方法确保了在修改期间没有其他人可以修改同一个文件,从而避免了冲突。然而,它也可能导致开发效率降低,因为其他开发者在等待锁释放时无法进行修改。
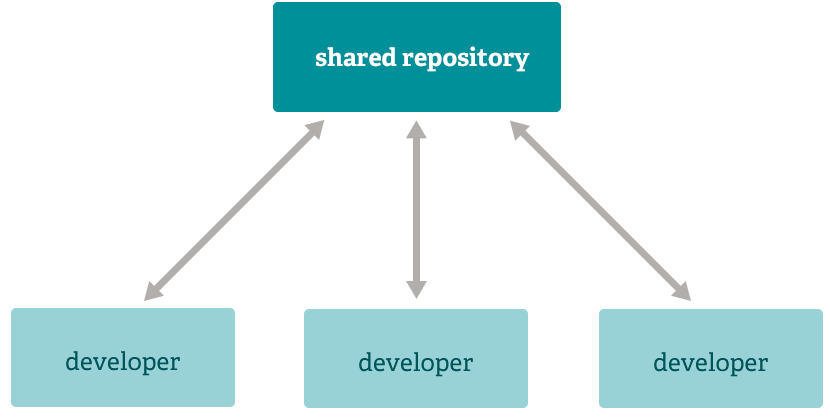
7.2.2 Copy-Modify-Merge
而在分布式版本控制系统,如git中,有了分支的概念。多个开发者可以把代码从远程仓库复制到本地,每个开发者可以在自己的分支上独立开发,并行工作(copy-modify);修改完成后,开发者可以将自己的分支合并到主分支,git会自动处理大部分的合并(merge)。
对文件的这些修改会被记录到项目的提交记录中。如果两个分支修改了同一文件的同一部分,那么这些修改将不会被自动合并,我们称之为冲突(conflict)。如果出现冲突,合并操作将暂停,直到冲突被手动解决。
为了避免不连续性,合并操作要么成功,要么失败,这是由事务机制实现的。事务(transaction) 相当于要一气呵成完成的一组操作,一个事务有两个开始事务和结束事务两个状态。在merge的过程中,对合并文件的一些检查会用一个log记录下来来进行检查,对事务的检查是不可中断的,如果发生冲突那么合并就会失败并回退到之前的状态(roll-back)并等待开发者的手动解决。
7.3 Linux-Only inotify
实际上,inotify应当被单拎出来。inotify是内核为我们提供的监视文件系统是否有事件发生的工具,它可以监控文件或目录的各种事件,如创建、删除、修改等。它本身并不是一个并发控制的工具,但一些情况下,inotify可以在并发控制中起到一些辅助的作用。
利用inotify API,你可以让你的程序对一些事件做出反应,比方说当某个文件被打开,程序做出一些响应。要让inotify给你发消息,你需要遵循以下步骤:
-
初始化并创建一个管理结构:使用
inotify_init函数初始化inotify实例,并获取一个文件描述符,用于管理这些事件。 -
添加监控事件:使用
inotify_add_watch函数告诉内核你想监控哪些事件,并将这些事件加入到inotify实例中。 -
读取事件:内核会通过文件描述符通知进程事件发生的信息。你可以使用
read函数读取这些事件,并根据需要进行处理。 -
关闭文件描述符:完成后,使用
close函数关闭文件描述符,释放资源。
值得注意的是,这个过程不是递归的。
7.3.1 inotify System Calls
我们有以下系统调用,初始化inotify的系统调用很好理解,即初始化创建一个inotify实例,一旦实例被创建,内核就会设置必要的数据结构和资源来管理inotify子系统。
#include <sys/inotify.h>
int inotify_init(void);
/*
Parameters: None
Return value: Returns a file descriptor for the inotify instance on success, otherwise -1.
*/

实例创建完之后,我们就要用inotify_add_watch()来指定你想要以监视的文件或目录。系统调用inotify_add_watch()会返回一个监视描述符,用于唯一标识的监视项(文件)。另一个系统调用inotify_rm_watch()是将特定的wd从inotify instance中删去。
int inotify_add_watch(int fd, const char *pathname, uint32_t mask);
/*
Parameters:
1. fd: File descriptor returned by inotify_init.
2. pathname: Path to the file or directory to be monitored.
3. mask: Bitmask of events to be monitored. Common events include:
- IN_ACCESS: File was accessed.(Read/Execute)
- IN_MODIFY: File was modified.(Write for example)
- IN_ATTRIB: Metadata changed.
- IN_CLOSE_WRITE: File opened for writing was closed.
- IN_CLOSE_NOWRITE: File not opened for writing was closed.
- IN_OPEN: File was opened.
- IN_MOVED_FROM: File was moved out of the watched directory.
- IN_MOVED_TO: File was moved into the watched directory.
- IN_CREATE: File or directory was created.
- IN_DELETE: File or directory was deleted.
- IN_DELETE_SELF: Watched file or directory was deleted.
Return value: Returns a watch descriptor on success, otherwise -1.
*/
int inotify_rm_watch(int fd, int wd);
/*
Parameters:
1. fd: File descriptor returned by inotify_init.
2. wd: Watch descriptor returned by inotify_add_watch.
Return value: Returns 0 on success, otherwise -1.
*/
7.3.2 Event Struct
之后你可以read(fd, buf, size),阻塞直到相应的事件发生。当你要监视的事件发生,inotify会将事件信息填充到 inotify_event 结构体中,并通过初始化得到的文件描述符返回给你。
struct inotify_event {
int wd; // Watch descriptor
uint32_t mask; // Bitmask of events that occurred
uint32_t cookie; // Unique cookie associating related events
uint32_t len; // Length of the name field
char name[]; // Optional null-terminated name of the file
};
由于最有一个字段是可选的,因而inotify_event结构体大小为:
event_size = sizeof(struct inotify_event) + inotify_event.len;
由于长度是不确定的,由此我们想要设置缓冲区时可能会设置的过大或过小。在设置缓冲区之前,我们可以用ioctl(inotify_fd, FIONREAD, &numbytes)先获取文件当前可读取的长度。但一般情况下,我们会用空间换时间。
7.3.2 An Example
#include <sys/inotify.h>
#include <unistd.h>
#include <fcntl.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <stdbool.h>
const char filename[] = "file.lock";
int main() {
int lockFD;
bool our_turn = false;
while (!our_turn) {
lockFD = open(filename, O_CREAT | O_EXCL | O_RDWR, 0666);
if (lockFD == -1) {
printf("The lock file is existing, and process %ld will wait...\n", (long)getpid());
int notifyFD = inotify_init();
uint32_t watch = inotify_add_watch(notifyFD, filename, IN_DELETE_SELF);
int buf_size = sizeof(struct inotify_event) + strlen(filename) + 1;
char* event_buffer = malloc(buf_size);
printf("Setup complete, waiting for event.\n");
// Read the file descriptor while the event happens.(blocking)
read(notifyFD, event_buffer, buf_size);
struct inotify_event* event = (struct inotify_event*)event_buffer;
printf("Event occurred!\n");
free(event_buffer);
inotify_rm_watch(notifyFD, watch);
close(notifyFD);
}
else {
int namelen = sizeof(filename);
write(lockFD, filename, namelen);
close(lockFD);
our_turn = true;
}
}
printf("Process %ld is in the critical area.\n", (long)getpid());
// remove(filename);
return 0;
}
第八课 Consistency Checking and Journalling
8.1 Data Consistency
我们用文件系统管理磁盘来存储我们所需要的数据。然而,由于某些情况,文件系统中也可能会发生数据的丢失或数据的不连续(如系统掉电而文件还没有来得及写回磁盘)。为了发现文件系统中数据的不连续,我们可以周期性地检查系统中不连续的数据。
但由于一个volume可能很大,而且磁盘又很慢,所以检查一个volume上是否有不连续性的数据会很耗费时间。因此,系统在运行时并不会主动扫描磁盘。一般而言,系统启动的时候或者用户下达命令时才会扫描volume。UNIX中,用户可以使用 fsck 系统调用来扫描磁盘;Windows中,则可以使用 chkdsk/scandisk。
8.1.1 Inconsistent State
那么,什么是不连续状态?文件不连续后操作系统会如何反应?我们提到了系统掉电而文件没有来得及写回磁盘的情况。当系统重新上电后,我们会发现一部分文件块由于掉电时在内存中而遗失掉了,这就是文件的不连续状态。不连续的文件可能会导致一些严重的问题。
例如,我们本来要创建一个大小10个块的文件,在FCB中文件大小字段中就将其标识为10个磁盘块。然而,之后的文件链表中只包含有5个块。当使用这些系统调用工具检查出不连续状态时,我们希望系统能够把遗失的块找回来并链在一起,但文件系统可能并不能这么做,文件系统会修改相关的信息(如FCB的文件大小字段修改为5),从而保证文件的连续性。
系统视角下的recovery和我们想象中的recovery好像并不太一样,但不论怎样,现在文件是连续的了,系统内没有错误了。任务完成!
8.1.2 Transaction
我们当然希望避免不连续问题的发生,以防因此出现严重的系统故障。避免因一些错误导致的数据不连续,你可能会想到原子操作。实际上,我们要使用避免数据不连续的方法事务其实我们可以看作原子操作的一种变种。事务使得操作要么完美地完成,要么就什么都不做。当今几乎所有的文件系统都会使用事务来避免data inconsistency的发生。
在版本控制系统和数据库中,为了使每个版本的数据都是连续的,这些软件会在修改文件相关结构之前,先列出一个待办事项清单。当这个待办事项清单中的所有待做项都完成之后,我们才会认为这个事务结束了,系统随之修改相关的数据结构。
8.1.3 Transaction in ZFS (Single-Atomic-Update)
ZFS使用single-atomic-update的事务机制来避免磁盘上的不连续性,这种机制类似于copy-modify-merge模型。数据先是从磁盘拷贝到内存,之后修改拷贝的磁盘块,最后将拷贝写回磁盘。这些修改后的新数据写回磁盘是并不会覆盖原旧数据块,而是将拷贝写到新磁盘块。这样其实为操作提供了冗余,如果写磁盘不连续,我们可以抛弃写回的数据块(即什么也不做)。如果操作一切顺利,那么我们就可以将旧磁盘块的引用用新的磁盘块所替代。
如果磁盘空间满了怎么办呢?那就买一块更大的后备硬盘吧!
8.2 APFS(Apple File System)
APFS引入了文件系统快照(snapshots),记录了某一时刻的文件系统状态。快照可以用于备份和恢复,确保在发生数据损坏或丢失时能够快速恢复到之前的状态。
8.3 NTFS(Windows FS)
8.3.1 NTFS Volume Layout
8.3.2 Transaction in NTFS
在NTFS中,所有对文件元数据的修改都会顺序地放到一个日志文件(log文件)中,一旦修改写入日志文件后,系统才会实际修改文件的元数据。这种机制被称为日志记录(journaling)。当系统修改完文件的元数据后,系统会将日志文件中标记为“已完成”的日志记录(事务)进行相应的清理。
之后,当系统崩溃,日志文件中就可能包括0个或多个事务待处理。0个当然最好,你不需要担心任何事;如果届时日志文件中有多个事务还没有处理,就意味着仍有事务没有完成。我们将有两种解决方案:前进和回退。
8.3.2.1 Roll-Forward
当系统上电后,如果这个清单可以接着之前的做,那当然最好,我们实际上并没有损失什么。比如下载软件到一半之后,系统掉电,但是上电后我们可以接着之前的继续下载。
8.3.2.2 Roll-Back
如果事务不能接着之前的做,系统就会回退到之前的版本,也就是在版本控制系统中常见的方式。
8.3.4 NTFS Journalling
在NTFS中,日志记录的实现如下:
-
当需要对文件元数据进行修改时,首先将这些修改记录在缓存中的日志文件里。这一步确保了所有修改操作都有一个记录,以防在实际写入磁盘之前发生故障。
-
在日志文件中记录修改后,系统会在缓存中进行实际的卷修改。这意味着这些修改还没有真正写入物理磁盘,但已经在内存中准备好了。
-
缓存管理器(cache manager)负责将缓存中的日志文件写入到物理磁盘上。这一步非常关键,因为它确保了日志记录的持久性,即使系统在此后崩溃,日志文件中的修改记录也不会丢失。
-
日志文件写入磁盘后,缓存管理器会开始将缓存中的卷修改写入到物理磁盘上。这一步确保了文件系统的一致性,因为即使在卷的实际修改过程中发生了系统故障,日志文件中的记录仍然可以用于恢复未完成的修改。